Releases: huggingface/trl
v0.13.0
Major and breaking changes
🐾 Process-supervised RM Trainer
We introduced a new trainer to train Process-supervised Reward Model (PRM) in TRL. A PRM rewards the quality of intermediate steps, promoting structured reasoning over focusing solely on the final outcome.With this trainer, we introduce a new dataset type: Stepwise supervision, which is a variant of the prompt-completion type, but for which completion is divided into several intermediate steps, and each step is associated with a label. Find out more in the stepwise-supervision section in the TRL documentation.
Here is an example of how to use the PRMTrainer to train a PRM on the Math Shepherd dataset:
# train_prm.py
from datasets import load_dataset
from trl import PRMConfig, PRMTrainer
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("Qwen/Qwen2-0.5B", num_labels=2)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
train_dataset = load_dataset("trl-lib/math_shepherd", split="train[:10%]")
training_args = PRMConfig(output_dir="Qwen2-0.5B-Reward-Math-Sheperd", logging_steps=10)
trainer = PRMTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
trainer.train()For more information, check out the PRMTrainer documentation.
by @qgallouedec and @gaetanlop in #2127 and #2148
🔀 Add MergeModelCallBack
Various works show that model merging can non-trivially improve performance, especially if the models belong to the same architecture. TRL now features a callback that merges the reference model with the current policy and optionally pushes the merged checkpoint to the Hub. This could be done on step/epoch end and/or the end of training. This callback uses Arcee's mergekit lib: https://github.com/arcee-ai/mergekit
from trl import DPOTrainer, MergeModelCallback
from trl.mergekit_utils import MergeConfig
config = MergeConfig()
merge_callback = MergeModelCallback(config)
trainer = DPOTrainer(..., callbacks=[merge_callback])by @August-murr in #2282
🔨 Support for tools for data utils
TRL preprocessing utils now support tooling. A first step toward agent fine-tuning.
from trl import apply_chat_template
def get_current_temperature(location: str):
"""
Gets the temperature at a given location.
Args:
location: The location to get the temperature for
"""
return 22.0
example = apply_chat_template(example, tokenizer, tools=[get_current_temperature])by @August-murr in #2455
🌋 Add support for LLaVA-Next in DPOTrainer
VLMs have their own specificities which require special treatment in the trainer. DPOTrainer now supports LLaVA-Next models natively.
model = model = AutoModelForVision2Seq.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
trainer = DPOTrainer(model=model, ...)by @chenweize1998 in #2413
🕹️ CLI and TRLParser refactor
TRL CLI has been refactored to be more user-friendly and easy to extend. We plan to extend the support to all trainers soon.
(simplified output, for readibility)
$ trl dpo --help
usage: trl dpo [-h] --dataset_name DATASET_NAME [--dataset_config DATASET_CONFIG] --output_dir OUTPUT_DIR [--loss_type {sigmoid,hinge,ipo}]
options:
-h, --help show this help message and exit
--dataset_name DATASET_NAME, --dataset-name DATASET_NAME
--dataset_config DATASET_CONFIG, --dataset-config DATASET_CONFIG
--output_dir OUTPUT_DIR, --output-dir OUTPUT_DIR
The output directory where the model predictions and checkpoints will be written. (default: None)
--loss_type {sigmoid,hinge,ipo}, --loss-type {sigmoid,hinge,ipo}by @qgallouedec in #2380 and #2412
🤝 Mixture of judges
TRL features a new judge AllTrueJudge that unifies the decision of multiple binary judges. This judge implements the Mixture of Judges as described in the CGPO paper.
from trl import AllTrueJudge, BaseBinaryJudge
class RandomBinaryJudge(BaseBinaryJudge):
"""
Random binary judge, for testing purposes.
"""
def judge(self, prompts, completions, gold_completions=None, shuffle_order=True):
return [random.choice([0, 1, -1]) for _ in range(len(prompts))]
prompts = ["The capital of France is", "The biggest planet in the solar system is"]
completions = [["Paris", "Marseille"], ["Saturn", "Jupiter"]]
judge = AllTrueJudge(judges=[RandomBinaryJudge(), RandomBinaryJudge()])
judgements = judge.judge(prompts=prompts, completions=completions)
print(judgements) # [0, 1]by @gaetanlop in #2159
❄️ DPO trainer supports num_logits_to_keep to save memory
Save memory by only keeping the top num_logits_to_keep logits in the DPO trainer.
training_args = DPOConfig(..., use_num_logits_to_keep=True)🗺️ Implementation DiscoPOP Loss
The DiscoPOP paper uses LLMs to discover more efficient offline preference optimization losses. In the paper the proposed DiscoPOP loss (which is a log-ratio modulated loss) outperformed other optimization losses on different tasks (IMDb positive text generation, Reddit TLDR summarization, and Alpaca Eval 2.0).
training_args = DPOConfig(..., loss_type="discopop", discopop_tau=0.05)🧑🍳 Add precompute batch size argument in DPOTrainer for reference model
We can now control the batch size for precomputing reference model logits.
training_args = DPOConfig(
...
precompute_ref_log_probs=True,
precompute_ref_batch_size=4,
)by @SwayamInSync in #2426
📦 Support for packing tokenized datasets for SFT
SFTTrainer has supported packing datasets for faster training. Now, it support packing tokenized datasets as well.
📉 Add PEFT support for PPOTrainer
PPOTrainer now supports PEFT for efficient training.
PPOTrainer(
...,
peft_config=peft_config,
)💾 Deprecate config in favor of args in PPOTrainer
config has been deprecated in favor of args in PPOTrainer.
PPOTrainer(
- config=training_args,
+ args=training_args,
)by @qgallouedec in #2384
👮 Deprecate policy in favor of model in PPOTrainer
policy has been deprecated in favor of model in PPOTrainer.
PPOTrainer(
- policy=model,
+ model=model,
)by @qgallouedec in #2386
What's Changed
- ⏫ Bump dev version to
0.13.0.dev0by @qgallouedec in #2305 - 📰 Update blog posts in documentation by @qgallouedec in #2319
- ⚰️ Remove deprecated args, script arguments, and PPOv2 by @qgallouedec in #2306
- 🧽 Fix judge doc by @qgallouedec in #2320
- 🪧 Fix slack notification titles by @qgallouedec in #2322
- 🪪 Check with
token_idinstead oftokeninDPOTrainerby @qgallouedec in #2324 - Fix wrong truncating index of tensor in DPOTrainer's concatenated_forward() by @yanghh2000 in #2332
- Fix gradient_checkpointing_kwargs assignment in examples by @Galaxy-Husky in #2331
- Bump liger-kernel to 0.4.0 by @ByronHsu in #2333
- DPO trainer supports num_logits_to_keep to save memory by @xyangk in #2129
- 🧞 Add
output_layerto the list oflm_head_namingsinAutoModelForCausalLMWithValueHeadby @qgallouedec in #2328 - 🫴 Better guide users in error reporting by @qgallouedec in #2327
- 🪡 Various RLOO fixes by @qgallouedec in #2325
- 💣 Remove transformers version check by @xyangk in #2343
- 👈 Add
tokenizerarg back and add deprecation guidelines by @qgallouedec in #2348 - 🖨️ Fix error text in BCO and KTO tokenizing function by @PhilipMay in #2286
- Adding video llm fine-tuning example by @mfarre in #2336
- 👋 Remove deprecated
tokenizerargument in BCO, GKD, Iterative SFT, Nash MD and XPO by @qgallouedec in #2349 - ⚖️ Add
use_soft_judgeoption toWinRateCallbackby @kashif in #2347 - 🪜 Stepwise supervision dataset type by @qgallouedec in #2148
- 🔮 Inference mode in
GeometricMixtureWrapper.forwardby @kashif in #2345 - 🗃️ Use specified
data_collatorinRLOOTrainerandPPOTrainerby @bartoszzuk in h...
Contributors
Assets 2
v0.12.2
v0.12.1
What's Changed
- 👈 Add
tokenizerarg back and add deprecation guidelines by @qgallouedec in #2348
Full Changelog: v0.12.0...v0.12.1
Contributors
Assets 2
v0.12.0
Major and breaking changes
General reward model support for Online DPO
Online DPO intially only supported a reward model that had the same tokenizer and chat template as the trained model. Now, you can use any reward model.
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer
from trl import OnlineDPOConfig, OnlineDPOTrainer
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_config.model_name_or_path, padding_side="left")
reward_model = AutoModelForSequenceClassification.from_pretrained(training_args.reward_model_path, num_labels=1)
reward_tokenizer = AutoTokenizer.from_pretrained(reward_model_name, truncation=True, truncation_side="left")
dataset = load_dataset(script_args.dataset_name)
training_args = OnlineDPOConfig(output_dir="...")
trainer = OnlineDPOTrainer(
model=model,
reward_model=reward_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
reward_processing_class=reward_tokenizer,
)
trainer.train()by @qgallouedec in #2276
Migration PPOv2 -> PPO
The PPOv2 trainer has been renamed to PPO. The old PPO trainer has been removed. PPOv2 is now deprecated and will be removed in the next release.
- trainer = PPOv2Trainer(...)
+ trainer = PPOTrainer(...)by @qgallouedec in #2174
Refactor ScriptArguments
We had ScriptArguments, SFTScriptArguments, DPOScriptArguments and RewardScriptArguments. Since they all share mostly the same fields, we've merged them into a single ScriptArguments class.
SFTScriptArguments, DPOScriptArguments and RewardScriptArguments still exist but are deprecated and will be removed in the next release.
- script_args = DPOScriptArguments(...)
+ script_args = ScriptArguments(...)by @qgallouedec in #2145
Soft judges for PairRM
The PairRMJudge now when called via the judge method has a flag return_scores that returns the probability scores of the first completion of the pair (instead of the rank of the preferred completion). The logits for the probability score can be scaled by an optional temperature parameter.
from trl import PairRMJudge
pairrm_judge = PairRMJudge()
prompts = ["Translate 'hello' to French", "What's the capital of Japan?"]
completions = [["Bonjour", "Salut"], ["Kyoto", "Tokyo"]]
results = pairrm_judge.judge(prompts, completions, return_scores=True)
print(results) # [0.7492601275444031, 0.0005497377132996917]Use pairwise judges for online methods
The OnlineDPOTrainer and any trainers that inherit from it (NashMDTrainer and XPOTrainer) can now accept an initialized PairwiseJudge instead of a reward model.
from datasets import load_dataset
from trl import OnlineDPOConfig, OnlineDPOTrainer, PairRMJudge
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
judge = PairRMJudge()
train_dataset = load_dataset("trl-lib/ultrafeedback-prompt", split="train")
training_args = OnlineDPOConfig(output_dir="Qwen2-0.5B-OnlineDPO", logging_steps=10)
trainer = OnlineDPOTrainer(
model=model, judge=judge, args=training_args, processing_class=tokenizer, train_dataset=train_dataset
)
trainer.train()Rename trainer arg tokenizer to processing_class
The tokenizer argument in the trainers has been renamed to processing_class to better reflect the fact that it can be not only a tokenizer but also a processor.
- trainer = DPOTrainer(model, args=training_args, train_dataset=dataset, tokenizer=tokenizer)
+ trainer = DPOTrainer(model, args=training_args, train_dataset=dataset, processing_class=tokenizer)tokenizer is still supported for SFTTrainer and DPOTrainer but deprecated and will be removed in the next release.
by @qgallouedec in #2162
Adding weighted preference optimization (WPO) to DPO
The WPO paper adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. To use this method, set the use_weighting flag to True in the [DPOConfig].
DPOConfig(..., use_weighting=True)

by @gaetanlop in #2141
🃏 Model card for TRL
Using trainer.push_to_hub() now automatically creates a model card that includes:
- A link to the base model used
- A link to the dataset used for training
- A link to the TRL repository
- Sample demo code
- A link to the associated Weights & Biases run
- A link to the paper detailing the training procedure
- Versions of dependencies
- BibTeX citations for both the training procedure and TRL
All links are properly formatted to allow cross-referencing, enabling traceability back to sources (e.g., the model appears linked on the paper’s page).
IOm_SdRMRwAvjfbB.mp4
by @qgallouedec in #2123
Minor
Conversational dataset support
You can now use conversational datasets directly, without needing to apply a chat template beforehand, for the following trainers:
BCOTrainer(by @qgallouedec in PR #2107)CPOTrainer(by @qgallouedec in PR #2144)DPOTrainer(by @qgallouedec in PR #2131)KTOTrainer(by @qgallouedec in PR #2248)ORPOTrainer(by @qgallouedec in PR #2184)
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import DPOTrainer
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
dataset = load_dataset(dataset_name, split="train")
# Not needed anymore:
#
# def process(row):
# prompt = tokenizer.apply_chat_template(example["prompt"], tokenize=False, add_generation_prompt=True)
# prompt_chosen = tokenizer.apply_chat_template(example["prompt"] + example["chosen"], tokenize=False)
# chosen = prompt_chosen[len(prompt) :]
# prompt_rejected = tokenizer.apply_chat_template(example["prompt"] + example["rejected"], tokenize=False)
# rejected = prompt_rejected[len(prompt) :]
# return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
#
# dataset = dataset.map(process)
training_args = DPOConfig(output_dir="...")
trainer = DPOTrainer(model, args=training_args, train_dataset=dataset, processing_class=tokenizer)
trainer.train()Refactor DPO data processing
For more information, see PR #2209.
trl env for printing system info
You can now use trl env to print system information, including the platform, Python version, PyTorch version, CUDA device(s), and versions of various libraries.
$ trl env
Copy-paste the following information when reporting an issue:
- Platform: Linux-5.15.0-1048-aws-x86_64-with-glibc2.31
- Python version: 3.11.9
- PyTorch version: 2.4.0
- CUDA device(s): NVIDIA H100 80GB HBM3
- Transformers version: 4.47.0.dev0
- Accelerate version: 0.19.0
- Accelerate config: not found
- Datasets version: 3.0.2
- HF Hub version: 0.26.1
- TRL version: 0.12.0+14ef1ab
- bitsandbytes version: 0.44.1
- DeepSpeed version: 0.15.3
- Diffusers version: 0.30.3
- Liger-Kernel version: 0.3.0
- LLM-Blender version: 0.0.2
- OpenAI version: 1.46.0
- PEFT version: 0.13.2
by @qgallouedec in #2104
Sequence-Level KD
From GKD paper:
Sequence-Level KD (Kim & Rush, 2016). SeqKD maximizes the likelihood of high probability sequences generated by the teacher, and can be viewed as supervised FT on teacher-generated outputs.
SeqKD is taken as a baseline in the paper. It is now possible to use Sequence-Level KD in the GKDTrainer by setting seq_kd=True in the GKDConfig.
training_args = GKDConfig(..., seq_kd=True)Default dataset_text_field to "text"
Since many users use "text" as the column name for textual data in datasets, we've made it the default (previously a required argument) in SFTConfig. Now, specifying dataset_text_field="text" is no longer necessary.
SFTConfig(
...,
- dataset_text_field="text",
)by @qgallouedec in #2078
What's Changed
- [SFT] fix neftune_noise_alpha in SFTTrainer by @kashif in #1841
- Standardize
training_argsby @qgallouedec in #2082 - Fix typo in ORPO example. by @skandermoalla in #2092
- Fix Inconsistency with IsShardedQLoRA Setting by @fabianlim in #2089
- Fixes #2087 - _process_tokens for empty prompts in KTOTrainer by @gabikadlecova in #2093
- KTO: fix logits metric, add logits metric to BCOTrainer by ...
Contributors
Assets 2
v0.11.4
What's Changed
- Fix Inconsistency with IsShardedQLoRA Setting by @fabianlim in #2089
New Contributors
- @fabianlim made their first contribution in #2089
Full Changelog: v0.11.3...v0.11.4
Contributors
Assets 2
v0.11.3
What's Changed
- [GKD] interpolate in prob. space by @kashif in #2204
- Drop
decoder_input_idsinDPOTrainerby @qgallouedec in #2208 - Update incorrect data processing in DataCollatorForChatML by @ruijunfeng in #2172
New Contributors
- @ruijunfeng made their first contribution in #2172
Full Changelog: v0.11.2...v0.11.3
Contributors
Assets 2
v0.11.2
Contributors
Assets 2
v0.11.1
Bug fix
Full Changelog: v0.11.0...v0.11.1
Contributors
Assets 2
v0.11.0
We are excited to introduce the new v0.11.0 release, with many new features and post-training algorithms. The highlights are as follows:
New post-training methods
Generalized Knowledge Distillation

Generalized Knowledge Distillation (GKD) is a post-training method from Google DeepMind that extends standard knowledge distillation by allowing the student to generate outputs during training and receive online feedback from the teacher. It consistently outperforms SFT and in some cases enables the student model to match the performance of the teacher, but with far fewer parameters.
To train models with this method, check out the GKDTrainer.
Exploratory Preference Optimization

Exploratory Preference Optimization is an online post-training method from researchers at Microsoft, MIT, and Wisconsin that extends DPO to incorporate online feedback from reward models or LLM judges. It is similar to online DPO, but has a slightly different theoretical basis concerning sample efficiency.
To train models with this method, check out the XPOTrainer.
Nash Learning with Human Feedback

Nash Learning with Human Feedback is a novel post-training method from Google DeepMind that uses pairwise preference models which are conditioned on two inputs, instead of the single one used in reward models. These preference models are then used to train a policy that consistently produces responses that are preferred over those from competing policies, thus approximating a Nash equilibrium (i.e. a two player game where actions are responses and payoffs are given by the preference model).
To train models with this method, check out the NashMDTrainer.
New trainer features
- Online DPO now supports training LoRA adapters with PEFT, which means you can dramatically reduce the amount of VRAM needed to train models with this method. By @qgallouedec in #2041
- The
OrpoTrainerhas better integration with PyTorchXLA for faster step time on TPUs ⚡ . By @wenxindongwork in #2001
Deprecations 🚨
- The
PPOTraineris marked for deprecated in favour ofPPOv2Trainerto provide a consistent API across TRL's trainers. It will be removed inv0.12.0. By @qgallouedec in #2016 - The
RichProgressCallbackhas been removed from the example scripts as it caused a variety of problems with logging in distributed environments. You can still use it by adding it manually to the trainer callbacks. By @lewtun in #2053
Bugfixes and improvements
- Adds experimental Liger support to SFT script by @edbeeching in #1992
- move slow-tests CI to new cluster by @glegendre01 in #1996
- [Online-DPO] fixes to the training scripts and setup.py by @kashif in #1997
- [pre-commit] update pre-commit yaml by @kashif in #2002
- [Docs] Add Liger-Kernel usage to SFTTrainer page by @ryankert01 in #2007
- [ci] pin numpy to < 2 on windows by @kashif in #2009
- Remove
promptsarg fromWinrateCallbackby @qgallouedec in #2010 - Allow
WinRateCallbackto be used without reference model by @qgallouedec in #2013 - Feat: Add support for APO-zero in KTOTrainer by @KarelDO in #1952
- Clean configs documentation by @qgallouedec in #1944
- Refactor reward modelling script to work with chat models by @lewtun in #2026
- correct formatting of star sign in kto_trainer.mdx by @mattany in #2031
- Remove unused functions in
core.pyby @northern-64bit in #2017 - Improves formatting of docstring + newlines by @northern-64bit in #2006
- Fix
packingdoc inSFTConfigand fix error when neitherdataset_text_fieldnorformatting_funcis provided. by @qgallouedec in #2035 - fix: unpackaging error in Custom Mixture of Experts model when
aux_loss_enabledis set to True. by @Jonathanjordan21 in #2039 - Drop canonical namespaces by @qgallouedec in #2048
- Change
non_eos_penaltyto be consistent acrossOnPolicytrainers by @RylanSchaeffer in #2033 - Temporary pin the transformers hash in the CI by @qgallouedec in #2049
- [XPO] xpo trainer by @kashif in #1943
- Fix logits compuation in KTO trainer prediction step by @issamemari in #2050
- [Draft, don't merge] Fix failing windows by @LysandreJik in #2051
- Clean up DPO example by @lewtun in #2043
- Remove
debugandsanity_checkargs by @qgallouedec in #2055 - Gkd trainer by @kashif in #1814
- Documentation dataset format by @qgallouedec in #2020
- Add missing autodocs by @qgallouedec in #2056
- Mask loss in gkd when generating from the student by @gaetanlop in #2058
- ©️ Copyrights by @qgallouedec in #2063
- Support for
SFTTrainer.evaluate()andSFTTrainer.predict()with null train_dataset by @Sohaib9920 in #2004 - make cuda-only tests device-agnostic by @faaany in #2044
- Make
ConstantLengthDataset(orpacking=True) shuffle examples before they are packed by @muupan in #2037 - Standardise API for
WinRateCallbackandLogCompletionsCallbackby @lewtun in #2061 - Fix dataset in GKD script by @lewtun in #2067
- [online models] remove min_new_tokens=args.max_new_tokens by @kashif in #2069
- Standardising datasets for testing by @qgallouedec in #2065
- [KTO] learning rate recomentations for kto by @kashif in #2070
- Nash md by @kashif in #1853
- Use
transformersutilities when possible by @qgallouedec in #2064 - Minor doc fixes and comments by @qgallouedec in #2073
- Added error check to RLOO, PPOv2, OnlineDPO that
ref_policyandpolicyhave different identities by @RylanSchaeffer in #2057 processor(prompt, images=image)toprocessor(images=image, text=prompt)by @qgallouedec in #2076- Use wrapped model for reference completions in
WinRateCallbackand set defaultfreqtoeval_stepsin LogCompletionsCallback` by @lewtun in #2074 - Conversational dataset support for Online DPO by @qgallouedec in #2075
- [WIP] Fix
logits/chosenandlogits/rejectedmetrics inkto_trainer. by @PhilipMay in #2077 - Standardize dataset naming by @qgallouedec in #2081
- Fix deepspeed for
PPOv2Trainerby @qgallouedec in #2080
New Contributors
- @AdnaneKhan made their first contribution in #1822
- @mkopecki made their first contribution in #1825
- @DZ9 made their first contribution in #1836
- @MAOJIASONG made their first contribution in #1840
- @davanstrien made their first contribution in #1845
- @eliebak made their first contribution in #1863
- @Rishav-hub made their first contribution in #1862
- @cemiu made their first contribution in #1738
- @SunMarc made their first contribution in #1919
- @karel-contextual made their first contribution in #1928
- @RylanSchaeffer made their first contribution in #1932
- @mina-parham made their first contribution in https://github.com/huggingface/trl/pull...
Contributors
Assets 2
v0.10.1
We are excited to introduce the new v0.10.1 release, with many new exciting features and post-training algorithms. The highlights are as follows:
Online DPO

Online DPO is a new alignment method from DeepMind to boost the performance of LLMs. With Online DPO, data is generated on the fly by the trained model (instead of pre-collected). For each prompt, two completions are generated, with a reward model selecting the preferred one. This approach:
- Eliminates the need for a pre-collected preference dataset (it's generated online)
- Enables continuous model improvement
- Yields better results than traditional DPO
To train models with this method, use the OnlineDPOTrainer
Liger Triton kernels for supercharged SFT

- We've integrated LinkedIn's Liger Triton kernels to the
SFTTrainerfor faster throughput and lower memory usage. To use them, setuse_liger_kernelinSFTConfig
DPO for VLMs
- We've added support to align vision-language models with DPO, now covering architectures LLaVa-1.5, PaliGemma, and Idefics2. To train VLMs with DPO, use the
dpo_visual.pyscript as follows
accelerate launch examples/scripts/dpo_visual.py \
--dataset_name HuggingFaceH4/rlaif-v_formatted \
--model_name_or_path google/paligemma-3b-pt-224 \
--trust_remote_code \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--output_dir dpo_paligemma_rlaif-v \
--bf16 \
--torch_dtype bfloat16WinRate callback for LLM as a judge
- We've added support to compute win rates over the reference model for methods like DPO. To do so, configure the callback to point to the LLM as judge API (OpenAI or Hugging Face Inference API) and then add:
trainer = DPOTrainer(...)
win_rate_callback = WinRateCallback(..., trainer=trainer)
trainer.add_callback(win_rate_callback)Anchored Preference Optimisation (APO) for fine-grained human/AI feedback
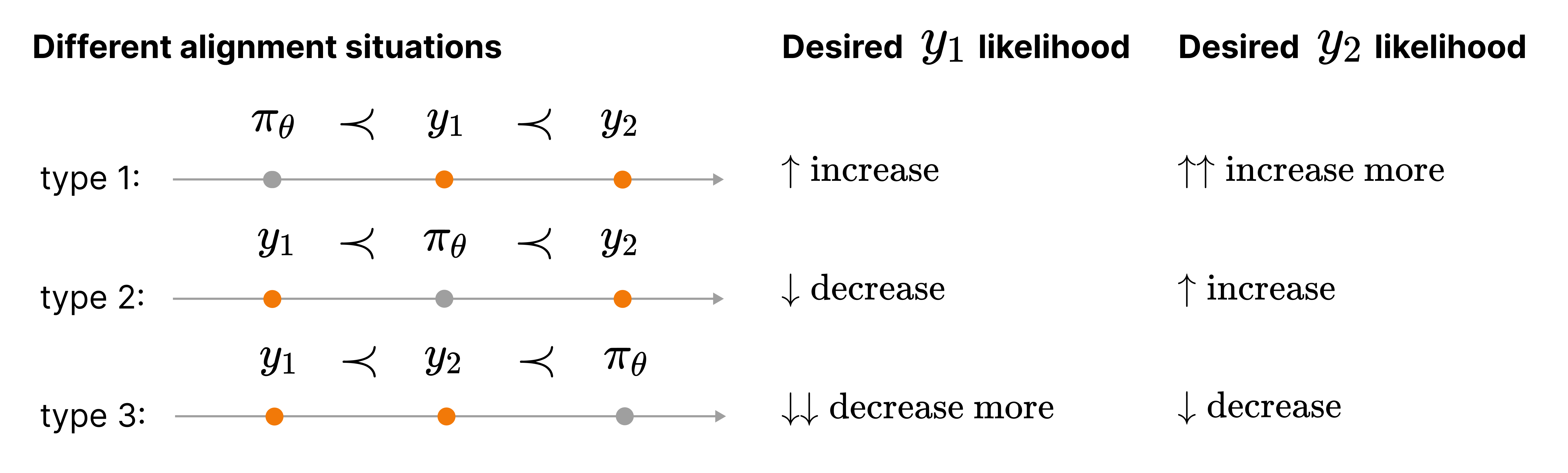
- Added the APO method, which is an "anchored" version of the alignment objective. There are two variants:
apo_zeroandapo_down. Theapo_zeroloss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand,apo_downdecreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. To use these losses, setloss_type="apo_zero"orloss_type="apo_down"in theDPOConfig
What's Changed
- Set dev version by @vwxyzjn in #1817
- Upgrade GitHub actions by @qgallouedec in #1818
- DPO Llava 1.5 and PaliGemma support by @qgallouedec in #1797
- Delete unused benchmark.yml workflow by @AdnaneKhan in #1822
- Consistent use of trust_remote_code by @qgallouedec in #1806
- Fix: authentication token kwarg not passed when loading PEFT adapters by @mkopecki in #1825
- refactor trainer callbacks by @kashif in #1826
- Uniform
model_refnaming by @qgallouedec in #1835 - fix ppov2_trainer tensorboard logging bug by @DZ9 in #1836
- Fix issues of KTOTrainer by @MAOJIASONG in #1840
- add link to DPO datasets collection by @davanstrien in #1845
- fix arg parsing in chat.py by @lvwerra in #1846
- DPO for VLM blog post in doc by @qgallouedec in #1844
- Add WinRateCallback and Judges by @lewtun in #1598
- Remove
CI_HUB_USER_TOKENby @qgallouedec in #1852 - Online DPO and Online trainer refactor by @vwxyzjn in #1809
- [online-DPO] online dpo cleanups by @kashif in #1864
- arXiv to HF Papers by @qgallouedec in #1870
- fix fsdp & qlora support by @eliebak in #1863
- Import missing
setup_chat_formatby @Rishav-hub in #1862 - Bug Fix while training using SFTTrainer with DataCollatorForCompletionOnlyLM by @Rishav-hub in #1861
- Small fixes to online dpo example by @edbeeching in #1879
- Skip BigBird save and load test until next transformers version by @qgallouedec in #1874
- Llama in modelling value head tests by @qgallouedec in #1878
- Improve judges by @qgallouedec in #1856
- [Do not merge] Re-add BigBird Pegasus save/load test by @qgallouedec in #1876
- Re-add BigBird Pegasus save/load test by @qgallouedec in #1882
- Move BCO to separate BCOTrainer with fixes by @claralp in #1869
- Update example overview documentation section by @qgallouedec in #1883
- fix dpo_trainer bug for LLMs without bos_token in config by @DZ9 in #1885
- Fix SFT for VLM example by @qgallouedec in #1865
evaluation_strategy->eval_strategyby @qgallouedec in #1894- fix serialization of RunningMoments on multiple GPUs by @claralp in #1892
- [WIP] Fix CI by @qgallouedec in #1897
- Drop
setUpClassin reward tester by @qgallouedec in #1895 - Support
IterableDatasetforSFTTrainerby @qgallouedec in #1899 - Fix data processing in ORPO example script by @qgallouedec in #1903
- [RPO] use loss from v3 of paper by @kashif in #1904
- Support Rank Stabilized LoRA in the ModelConfig/LoraConfig by @JohnGiorgi in #1877
- [Online-DPO] num_generation_per_prompt is fixed by @kashif in #1898
- Fix GPT2 sentiment notebook reward by @cemiu in #1738
- Fix
AlignPropTrainerimport by @qgallouedec in #1908 - Various args and test fix by @qgallouedec in #1909
lr_scheduler.step()afteroptimizer.step()by @qgallouedec in #1918torch.cuda.amp.autocast()->torch.amp.autocast("cuda")by @qgallouedec in #1921- Fix orpo trainer loss device by @SunMarc in #1919
- Add transformers library name for TRL repos by @lewtun in #1922
- Standardize
dataset_num_procusage by @qgallouedec in #1925 PartialState().local_main_process_first()when map in examples by @qgallouedec in #1926- minor BCO fixes by @claralp in #1923
- Improve DPO/loss doc by @qgallouedec in #1929
- feat: anchored pref optimization by @karel-contextual in #1928
- Add tests for DPO for VLM by @qgallouedec in #1935
- fix model to save in ppov2 by @mnoukhov in #1776
- Optional Additional Loss to Center Reward Models' Outputs by @RylanSchaeffer in #1932
- Properly label all models when pushed to the hub by @qgallouedec in #1940
- Skip token in
push_to_hubby @qgallouedec in #1945 - Fix model wrapping for online DPO by @lewtun in #1946
- Don't mark issues as stale if nobody answered by @qgallouedec in #1949
- Add a simple-to-understand example for online DPO by @vwxyzjn in #1947
- Log WandB tables on main process by @lewtun in #1951
- [ODPO] Fix global step for consistent checkpointing with global updates by @lewtun in #1950
- "help wanted" in label to exempt from stale by @qgallouedec in #1956
- Fix response truncation in examples/notebooks/gpt2-sentiment.ipynb by @qgallouedec in #1957
- [ODPO] Refactor training script to use messages API by @lewtun in #1958
- Support LLaVA-NeXT in Vision SFT by @qgallouedec in #1959
- Add i...