-
Notifications
You must be signed in to change notification settings - Fork 780
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Add] Logits Processor Zoo with HF Transformers (#2524)
* add logits processor zoo * add ahmet's username * review suggestions * chore: review suggestions * Apply suggestions from code review Co-authored-by: Pedro Cuenca <[email protected]> * chore: review suggestions * update date * Update logits-processor-zoo.md Co-authored-by: Pedro Cuenca <[email protected]> * chore: updating date --------- Co-authored-by: Pedro Cuenca <[email protected]>
- Loading branch information
Showing
3 changed files
with
353 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,343 @@ | ||
| --- | ||
| title: "Controlling Language Model Generation with NVIDIA's LogitsProcessorZoo" | ||
| thumbnail: /blog/assets/logits-processor-zoo/thumbnail.png | ||
| authors: | ||
| - user: ariG23498 | ||
| - user: aerdem4 | ||
| guest: true | ||
| org: nvidia | ||
| --- | ||
|
|
||
| # Controlling Language Model Generation with NVIDIA's LogitsProcessorZoo | ||
|
|
||
| Generating text with language models often involves selecting the next token based on a distribution of probabilities. | ||
| A straightforward approach like **greedy search** selects the most probable token, but this can result in generic or repetitive outputs. | ||
| To add diversity and control, more advanced **decoding strategies**, such as beam search, nucleus sampling, and top-k sampling, are widely used. | ||
| These strategies, supported by the [🤗 Transformers library](https://huggingface.co/docs/transformers/en/generation_strategies), | ||
| give us flexibility in shaping the model's outputs. | ||
|
|
||
| But what if we wanted to go a step further and **control the text generation process itself** by directly modifying the probability distribution? | ||
| That’s where **logit processing** comes into play. Hugging Face's [LogitsProcessor API](https://huggingface.co/docs/transformers/en/internal/generation_utils#logitsprocessor) | ||
| lets you customize the prediction scores of the language model head, providing granular control over model behavior. | ||
| The 🤗 Transformers library not only offers a rich set of built-in logits processors but also empowers the community | ||
| to create and share custom processors tailored to unique use cases. | ||
|
|
||
| Enter NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo/tree/main) — a collection of powerful, modular logits processors | ||
| designed for specific tasks such as controlling sequence lengths, enforcing key phrases, or guiding multiple-choice answers. | ||
| Fully compatible with Hugging Face's [`generate`](https://huggingface.co/docs/transformers/v4.47.1/en/main_classes/text_generation#transformers.GenerationMixin.generate) | ||
| method, NVIDIA’s library serves as an excellent example of community-driven innovation in logits processing. | ||
|
|
||
| In this post, we’ll explore how NVIDIA’s LogitsProcessorZoo enhances and expands on existing capabilities, diving deep into its features and demonstrating how it can refine your AI workflows. | ||
|
|
||
| ## What Are Logits in Language Models? | ||
|
|
||
| 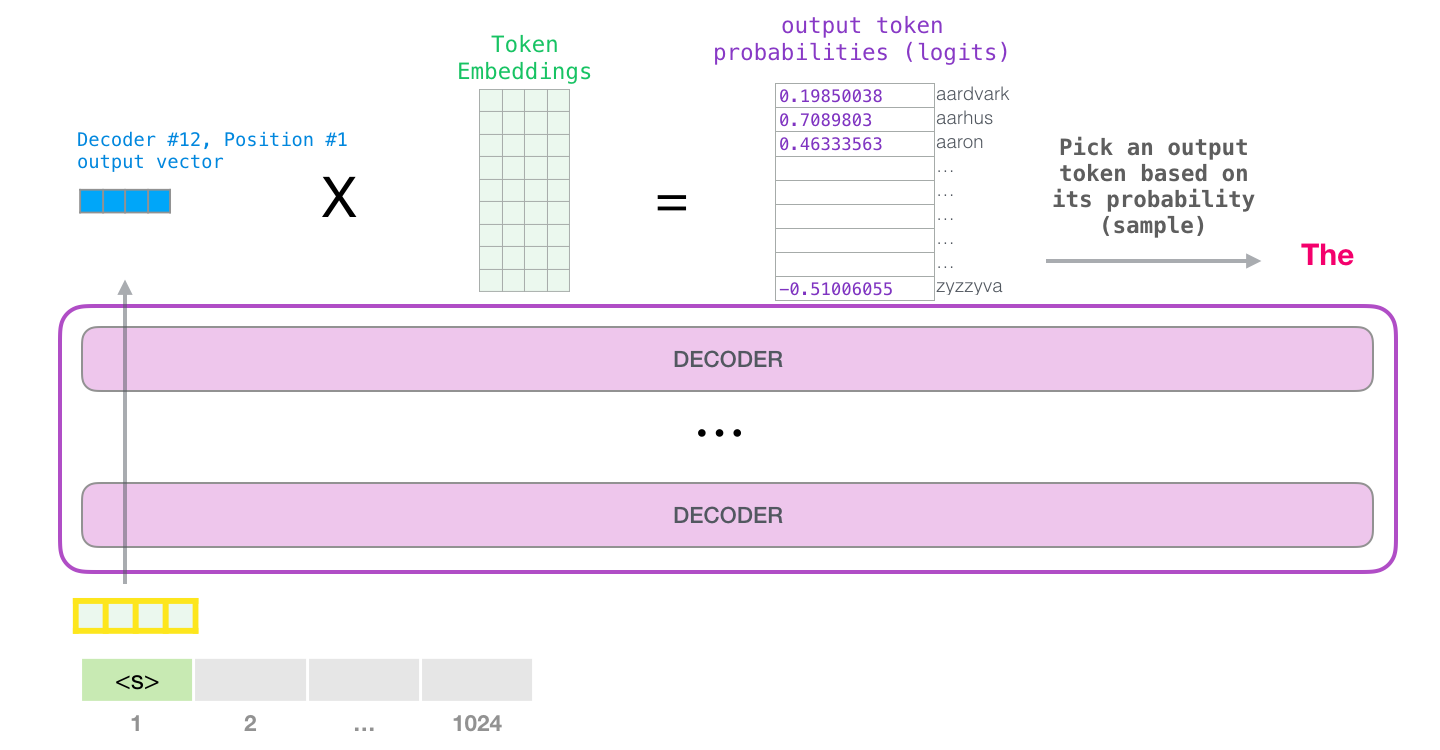 | ||
| Taken from: https://jalammar.github.io/illustrated-gpt2/ | ||
|
|
||
| Logits are the raw, unnormalized scores generated by language models for each token in their vocabulary. These scores are transformed into probabilities via the **softmax** function, guiding the model in selecting the next token. | ||
|
|
||
| Here's an example of how logits fit into the generation process: | ||
|
|
||
| ```python | ||
| from transformers import AutoTokenizer, AutoModelForCausalLM | ||
| import torch | ||
|
|
||
| # Load a model and tokenizer | ||
| model_name = "meta-llama/Llama-3.2-1B" | ||
| tokenizer = AutoTokenizer.from_pretrained(model_name) | ||
| model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto") | ||
|
|
||
| # Input text | ||
| prompt = "The capital of France is" | ||
| inputs = tokenizer(prompt, return_tensors="pt").to(model.device) | ||
|
|
||
| # Get logits | ||
| with torch.inference_mode(): | ||
| outputs = model(**inputs) | ||
| logits = outputs.logits | ||
|
|
||
| # Logits for the last token | ||
| last_token_logits = logits[:, -1, :] | ||
| ``` | ||
|
|
||
| These logits represent the model's confidence for each potential next word. Using softmax, we can turn them into probabilities and decode them into the generated text: | ||
|
|
||
| ```python | ||
| # Prediction for the next token | ||
| next_token_probs = torch.nn.functional.softmax(last_token_logits, dim=-1) | ||
|
|
||
| # Decode logits to generate text | ||
| predicted_token_ids = torch.argmax(next_token_probs, dim=-1) | ||
| generated_text = tokenizer.batch_decode(predicted_token_ids, skip_special_tokens=True) | ||
| print("Generated Text:", generated_text[0]) | ||
|
|
||
| >>> Generated Text: Paris | ||
| ``` | ||
|
|
||
| While this pipeline demonstrates how raw logits can be transformed into text, it's worth noting that 🤗 Transformers streamlines this process. | ||
| For instance, the [`generate()`](https://huggingface.co/docs/transformers/en/main_classes/text_generation) method automatically handles these | ||
| transformations, including applying the softmax function and sampling from the probability distribution. | ||
|
|
||
| However, raw logits may be undesirable for common tasks like sampling or imposing task-specific constraints. For more details on handling logits | ||
| effectively during generation, refer to Hugging Face's [generation blog post](https://huggingface.co/blog/how-to-generate). | ||
| This is where **logit processing** becomes indispensable to tailor the output to specific needs. | ||
|
|
||
| ## Why Process Logits? | ||
|
|
||
| Raw logits often fall short when controlling output behavior. For example: | ||
|
|
||
| - **Lack of constraints:** They might not adhere to required formats, grammar rules, or predefined structures. | ||
| - **Overgeneralization:** The model could prioritize generic responses instead of specific, high-quality outputs. | ||
| - **Task misalignment:** Sequences may end too early, be overly verbose, or miss critical details. | ||
|
|
||
| Logit processing enables us to tweak the model's behavior by modifying these raw scores before generation. | ||
|
|
||
| ## NVIDIA's LogitsProcessorZoo | ||
|
|
||
| NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo) simplifies post-processing of logits with modular components tailored for specific tasks. | ||
| Let's explore its features and see how to use them. To follow along, head over to | ||
| [the notebook](https://huggingface.co/datasets/ariG23498/quick-notebooks/blob/main/nvidia-logits-processor-zoo.ipynb) and experiment with the logits processors. | ||
|
|
||
| Install the library using: | ||
|
|
||
| ```bash | ||
| pip install logits-processor-zoo | ||
| ``` | ||
|
|
||
| To demonstrate the processors, we'll create a simple `LLMRunner` class that initializes a model and tokenizer, | ||
| exposing a `generate_response` method. We will then provide different processors to the `generate_response` method and see them in action. | ||
|
|
||
| ```python | ||
| # Adapted from: https://github.com/NVIDIA/logits-processor-zoo/blob/main/example_notebooks/transformers/utils.py | ||
| class LLMRunner: | ||
| def __init__(self, model_name="meta-llama/Llama-3.2-1B-Instruct"): | ||
| self.tokenizer = AutoTokenizer.from_pretrained(model_name) | ||
|
|
||
| self.model = AutoModelForCausalLM.from_pretrained( | ||
| model_name, | ||
| torch_dtype=torch.bfloat16, | ||
| device_map="auto", | ||
| ) | ||
|
|
||
| def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000): | ||
| if logits_processor_list is None: | ||
| logits_processor_list = [] | ||
|
|
||
| for prompt in prompts: | ||
| conversation = [ | ||
| {"role": "system", "content": "You are a helpful assistant."}, | ||
| {"role": "user", "content": prompt}, | ||
| ] | ||
| inputs = self.tokenizer.apply_chat_template( | ||
| conversation, | ||
| tokenize=True, | ||
| add_generation_prompt=True, | ||
| return_tensors="pt", | ||
| return_dict=True, | ||
| ).to(self.model.device) | ||
|
|
||
| outputs = self.model.generate( | ||
| **inputs, | ||
| max_new_tokens=max_tokens, | ||
| min_new_tokens=1, | ||
| logits_processor=LogitsProcessorList(logits_processor_list), | ||
| ) | ||
|
|
||
| gen_output = self.tokenizer.batch_decode( | ||
| outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False | ||
| ) | ||
| # Extract only the generated output after the original input length | ||
| generated_text = gen_output[0][ | ||
| len( | ||
| self.tokenizer.decode( | ||
| inputs["input_ids"][0], skip_special_tokens=True | ||
| ) | ||
| ) : | ||
| ].strip() | ||
|
|
||
| print(f"Prompt: {prompt}") | ||
| print() | ||
| print(f"LLM response:\n{generated_text}") | ||
|
|
||
| runner = LLMRunner() | ||
| ``` | ||
|
|
||
| ### 1. GenLengthLogitsProcessor | ||
|
|
||
| Control the length of generated sequences by adjusting the likelihood of the end-of-sequence (EOS) token. | ||
|
|
||
| This processor is particularly useful in scenarios where the desired length of generated text plays a | ||
| crucial role, such as generating concise summaries, restricting verbose outputs, or tailoring responses | ||
| to specific use cases. For instance, it can help ensure that a chatbot provides short and meaningful | ||
| responses while maintaining grammatical integrity by completing sentences when required. | ||
|
|
||
| ```py | ||
| example_prompts =[ | ||
| "Tell me a story about a kid lost in forest." | ||
| ] | ||
|
|
||
| # generate short response | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [GenLengthLogitsProcessor(runner.tokenizer, boost_factor=0.1, p=2, complete_sentences=True)] | ||
| )) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| Once upon a time, in a dense forest, there lived a young boy named Timmy. Timmy was on a family camping trip with his parents and little sister, Emma. They had been walking for hours, and the dense trees seemed to close in around them. As the sun began to set, Timmy realized he had wandered away from his family. | ||
| At first, Timmy didn't panic. He thought about calling out for his parents and Emma, but his voice was hoarse from singing campfire songs. He looked around, but the trees seemed to stretch on forever, making it impossible to see any familiar landmarks. As the darkness grew thicker, Timmy's fear began to creep in. | ||
|
|
||
| ```py | ||
| # generate long response | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [GenLengthLogitsProcessor(runner.tokenizer, boost_factor=-10.0, p=0, complete_sentences=False)] | ||
| )) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| Once upon a time, in a dense and vibrant forest, there lived a young boy named Max. Max was an adventurous and curious 8-year-old who loved exploring the outdoors. One sunny afternoon, while wandering through the forest, he stumbled upon a narrow path he had never seen before. | ||
| Excited by the discovery, Max decided to follow the path and see where it would lead. The forest was teeming with life, and the sunlight filtering through the trees created a magical atmosphere. Max walked for about 20 minutes, his eyes scanning the surroundings for any signs of civilization. | ||
| As the sun began to set, casting a warm orange glow over the forest, Max realized he was lost. He had no phone, no wallet, and no way to communicate with his family. Panic started to set in, and Max began to feel scared and alone. | ||
| Panicked, Max started to run through the forest, his heart racing and his legs trembling. He stumbled upon a clearing and saw a faint light in the distance. As he approached, he saw a small cabin in the center of the clearing. Smoke was rising from the chimney, and Max could hear the sound of someone singing a gentle tune. | ||
| ... | ||
|
|
||
| In the examples above, we have used the `GenLengthLogitsProcessor` to both shorten and lengthen the | ||
| response generated by the model. | ||
|
|
||
| ### 2. CiteFromPromptLogitsProcessor | ||
|
|
||
| Boost or diminish tokens from the prompt to encourage similar outputs. | ||
|
|
||
| This is particularly valuable in tasks requiring context retention, such as answering questions based | ||
| on a passage, generating summaries with specific details, or producing consistent outputs in dialogue systems. | ||
| For example, in the given code snippet where a user review is analyzed, this processor ensures the | ||
| model generates a response closely tied to the review's content, such as emphasizing opinions about | ||
| the product's price. | ||
|
|
||
| ```py | ||
| example_prompts =[ | ||
| """ | ||
| A user review: very soft, colorful, expensive but deserves its price, stylish. | ||
| What is the user's opinion about the product's price? | ||
| """, | ||
| ] | ||
|
|
||
| # Cite from the Prompt | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [CiteFromPromptLogitsProcessor(runner.tokenizer, example_prompts, boost_factor=5.0)], | ||
| max_tokens=50, | ||
| )) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| Based on the user review, the user's opinion about the product's price is: the user is very satisfied, but the price is expensive, but the product is stylish, soft, and colorful, which is the price the user is willing to pay | ||
|
|
||
| Notice how the generation cites the input prompt. | ||
|
|
||
| ### 3. ForceLastPhraseLogitsProcessor | ||
|
|
||
| Force the model to include a specific phrase before ending its output. | ||
|
|
||
| This processor is especially useful in structured content generation scenarios where consistency or | ||
| adherence to a specific format is crucial. It is ideal for tasks like generating citations, | ||
| formal reports, or outputs requiring specific phrasing to maintain a professional or organized presentation. | ||
|
|
||
| ```py | ||
| example_prompts = [ | ||
| """ | ||
| Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur | ||
| Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise. | ||
| Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon. | ||
| Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise. | ||
| It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May. | ||
| It is featured in various manga and is owned by protagonist Red in Pokémon Adventures. | ||
| What is Bulbasaur? | ||
| """, | ||
| ] | ||
|
|
||
|
|
||
| phrase = "\n\nReferences:" | ||
| batch_size = len(example_prompts) | ||
|
|
||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)] | ||
| )) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| According to the information retrieved from the Wikipedia article, Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, and it has been featured in various forms of media, including: | ||
| - As a starter Pokémon in the first generation of Pokémon games, including Pokémon Red and Blue. | ||
| - As a main character in the Pokémon anime, where it is one of Ash Ketchum's first Pokémon. | ||
| - As a character in the Pokémon manga, where it is owned by protagonist Red. | ||
| - As a character in various other Pokémon media, such as spin-off games and related merchandise. | ||
| Bulbasaur is also a central character in the Pokémon franchise, often appearing alongside other Pokémon and being a key part of the Pokémon world. | ||
| References: | ||
| - https://en.wikipedia.org/wiki/Bulbasaur | ||
|
|
||
|
|
||
| ```py | ||
| phrase = "\n\nThanks for trying our RAG application! If you have more questions about" | ||
|
|
||
| print(runner.generate_response(example_prompts, | ||
| [ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)] | ||
| )) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, characterized by its distinctive appearance. | ||
| Thanks for trying our RAG application! If you have more questions about Bulbasaur, feel free to ask. | ||
|
|
||
| With each generation we were able to add the `phrase` string right before the end of the generation. | ||
|
|
||
| ### 4. MultipleChoiceLogitsProcessor | ||
|
|
||
| Guide the model to answer multiple-choice questions by selecting one of the given options. | ||
|
|
||
| This processor is particularly useful in tasks requiring strict adherence to a structured answer format, | ||
| such as quizzes, surveys, or decision-making support systems. | ||
|
|
||
| ```py | ||
| example_prompts = [ | ||
| """ | ||
| I am getting a lot of calls during the day. What is more important for me to consider when I buy a new phone? | ||
| 0. Camera | ||
| 1. Battery | ||
| 2. Operating System | ||
| 3. Screen Resolution | ||
| Answer: | ||
| """, | ||
| ] | ||
|
|
||
| mclp = MultipleChoiceLogitsProcessor( | ||
| runner.tokenizer, | ||
| choices=["0", "1", "2", "3"], | ||
| delimiter="." | ||
| ) | ||
|
|
||
| print(runner.generate_response(example_prompts, [mclp], max_tokens=1)) | ||
| ``` | ||
|
|
||
| > LLM response: | ||
| 1 | ||
|
|
||
| Here our model does not generate anything other than the choice. This is an immensely helpful attribute while | ||
| working with agents or using models for multiple choice questions. | ||
|
|
||
| ## Wrapping Up | ||
|
|
||
| Whether you are generating concise summaries, crafting chatbot responses, or solving structured tasks like multiple-choice questions, logit processors provide the flexibility to control outputs effectively. This makes them invaluable for scenarios where precision, adherence to constraints, or task-specific behavior is critical. | ||
|
|
||
| If you're interested in exploring more about how to control generation with logit processors, here are some resources to get started: | ||
|
|
||
| - [How to Generate Text with Transformers](https://huggingface.co/blog/how-to-generate) – A beginner-friendly guide to understanding text generation in 🤗 Transformers. | ||
| - [Hugging Face: Generation Strategies](https://huggingface.co/docs/transformers/en/generation_strategies) – Learn about decoding strategies like greedy search, beam search, and top-k sampling. | ||
| - [Hugging Face: LogitsProcessor API](https://huggingface.co/docs/transformers/en/internal/generation_utils#logitsprocessor) – Dive deeper into how logits processing works in 🤗 Transformers and how to create custom logits processors. | ||
| - [NVIDIA's LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo) – Explore the full range of logits processors available in NVIDIA’s library with examples and use cases. | ||
|
|
||
| With NVIDIA's LogitsProcessorZoo and Hugging Face's tools, you have a robust ecosystem to take your language model applications to the next level. Experiment with these libraries, build custom solutions, and share your creations with the community to push the boundaries of what's possible with generative AI. |