{kind=link}
{kind=link}
It takes in CSV files and spits out a matplotlib graph of the results
You must edit the code to use your files for now, but argument processing wouldnt be that hard to implement
CSV format: THREADS, BUCKETS, DURATION
To use benchmark_graph_util.py
- run pip3 install matplotlib
- edit the bottom of the script to add the benchmarks you want to graph
To use benchmark_util.py:
- open it in a text editor and add your public pool contract key (p2 singleton address) and your farming public key. Configure the directories and thread/bucket lists
- Save and exit
- Run the script using python3, the directory the terminal is in will be where the CSV file is saved to
- Take care to rename the benchmark file after it is done as the script will just append data to it if run again
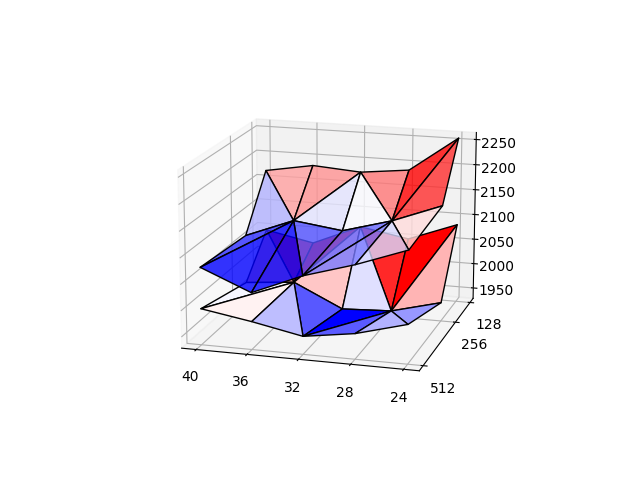
Example of my rigs benchmark:
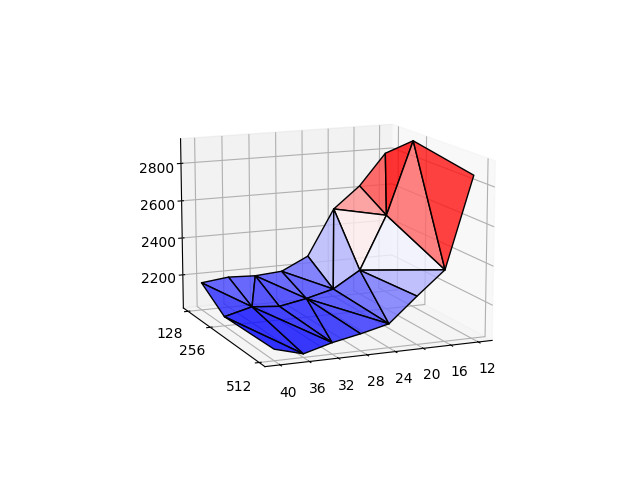
Example of the difference between a single disk and an LVM RAID0:
(Top is single disk, bottom is RAID0 of 2 disks)