B.Sc in Business, Accounting & Finance
Chartered Certified Accountant
Life-long learner, AI & Big Data enthusiast
Data Solutions Engineer @ PricewaterhouseCoopers Ltd
Some of the projects I've led include but are not limited to:
- Real-Time Streaming Data Platform
Project Vision: To build a data platform as a web-app, integrated with the company's ERP and databases, that can handle large volumes of structured and semi-structured data in real time, transform it into accounting double entries and post it into the ERP accordingly. All operations and records must also be stored and maintained effectively and efficiently in the data warehouse. Clickstream data must also be analyzed in real time to provide insights that will assist the continuous improvement/continuous development effort. For data security and monitoring best practises, data anomalies must be detected in real-time and the relevant teams must be notified immediately.
My role: As the development lead, I had the opportunity to be included in all stages of the project's lifecycle. From gathering and documenting requirements from all stakeholders during the business analysis sessions, to building prototype ETL pipelines that collect and transform data according to accounting & business requirements in real time from various sources, to delivery of the final product, including unit testing, QA testing, end-user training sessions and incorporation of improvements collected from various stakeholders' feedback during the ongoing CI/CD cycle.
Outcome: This platform is to date the most used data solution within the company, enabling staff to process far bigger amounts of transactions than they could before, in a tiny fraction of the time, with a much higher accuracy. Human errors were elimited by 98% and the newly achieved efficiencies allowed the company to take on a much higher amount of work with the same amount of staff, significantly increasing profits. The project's success underscored the need for further funding of my team, and we grew from 3 people to over 20 in the span of a couple of years. As the most senior member in the team after my Senior Project Manager, I was responsible for personally mentoring and onboarding every new team member.
- Multi-Cloud Data Lake Solution
Project Vision: To create a secure, scalable multi-cloud data lake that consolidates data across AWS, GCP, and Azure, facilitating advanced analytics and data governance practices.
My Role: As the lead architect, I orchestrated the project's lifecycle, from planning to execution, ensuring seamless integration of cloud services and optimal performance. My responsibilities included architecting the data lake structure, selecting cloud-native services for storage and processing, and establishing data governance protocols.
Outcome: The establishment of a highly accessible and compliant multi-cloud data lake that streamlined data operations and enabled sophisticated analytics capabilities, driving better business decisions.
Technical Details: Utilized AWS S3 for durable, scalable storage, integrated with GCP BigQuery for powerful analytics, and Azure Data Lake for additional storage solutions, ensuring a robust data governance framework. Apache Spark on Databricks facilitated cross-cloud data processing, with Terraform scripts for infrastructure as code (IaC) ensuring consistent deployment across clouds. Data security and compliance were enforced through stringent IAM policies and encryption both at rest and in transit.
- Predictive Analytics for Customer Churn
Project Vision: To develop a predictive analytics model that identifies potential customer churn, enabling proactive customer retention strategies.
My Role: I led the data science efforts, from data preparation and model building to deployment and visualization. My focus was on leveraging real-time data streams to feed into the predictive model and presenting actionable insights through dashboards.
Outcome: A dynamic predictive model that significantly improved customer retention rates by enabling timely interventions, thus enhancing overall customer satisfaction and loyalty.
Technical Details: The solution combined Python and PySpark for model development, with AWS Lambda for model deployment, ensuring scalability and cost-efficiency. AWS Kinesis streamed real-time data, feeding into the churn prediction model. PowerBI and Tableau were used to create interactive dashboards that presented churn predictions and customer behavior insights, facilitating swift action by the customer service teams.
- Automated Data Quality Framework
Project Vision: To implement an automated framework for continuous data quality monitoring and anomaly detection across real-time data streams.
My Role: As the principal engineer, I was responsible for designing the framework, integrating Kafka with DataDog for monitoring, and setting up PagerDuty notifications for alerts.
Outcome: A robust framework that ensured high levels of data integrity and reliability, significantly reducing the time and resources spent on identifying and rectifying data issues.
Technical Details: Leveraged Apache Kafka for real-time data ingestion, with custom Kafka Streams applications to perform on-the-fly data quality checks. Integrated DataDog for comprehensive monitoring of data pipelines and Kafka metrics, and utilized PagerDuty for automated incident management and alerting. This setup allowed for immediate detection and notification of data anomalies, streamlining the resolution process.
The below dashboard samples are one of many BI solutions I've worked on. They are fed real-time data through SQL queries connecting directly to the data warehousing solution being used - once hosted in a domain with proper access right setup, it is completely interactive. Dummy data is displayed in screenshots for demo purposes.
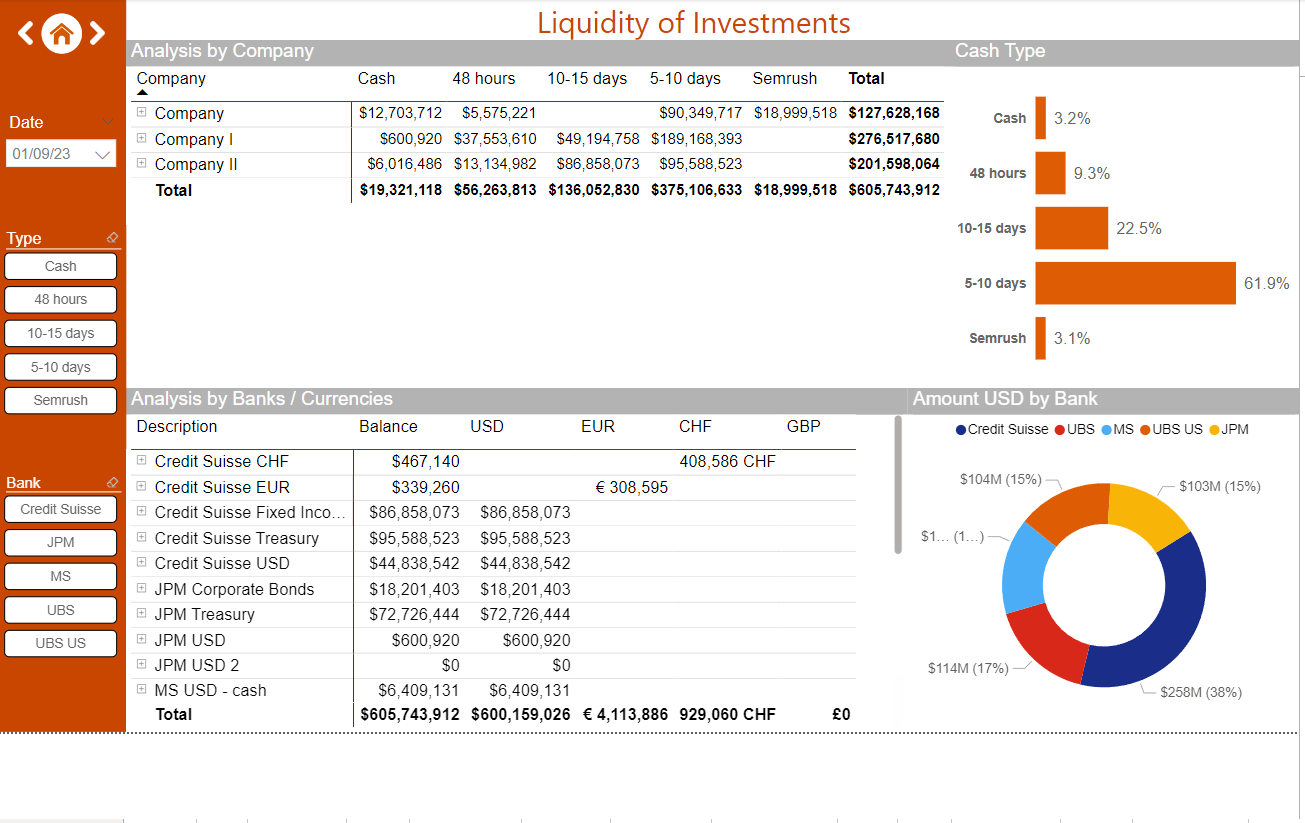
- Detailed breakdown of investment liquidity
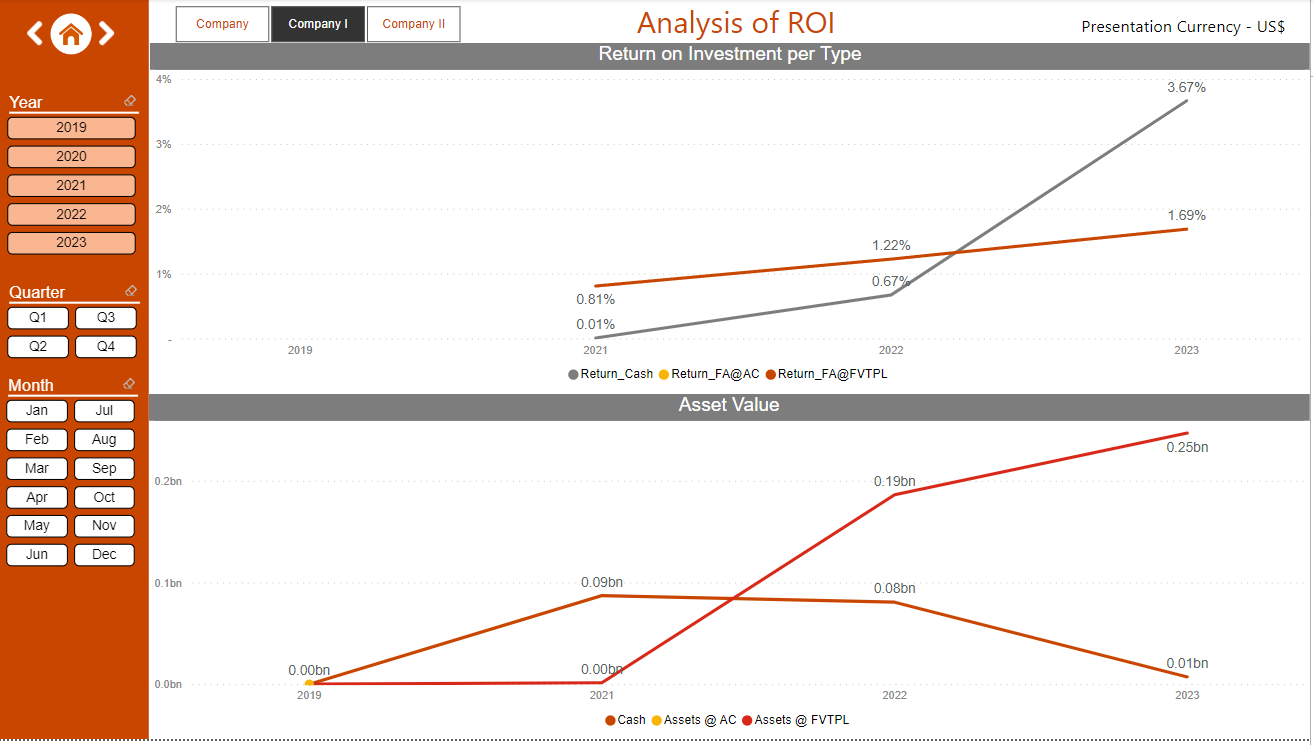
- Trend analysis of return on investment
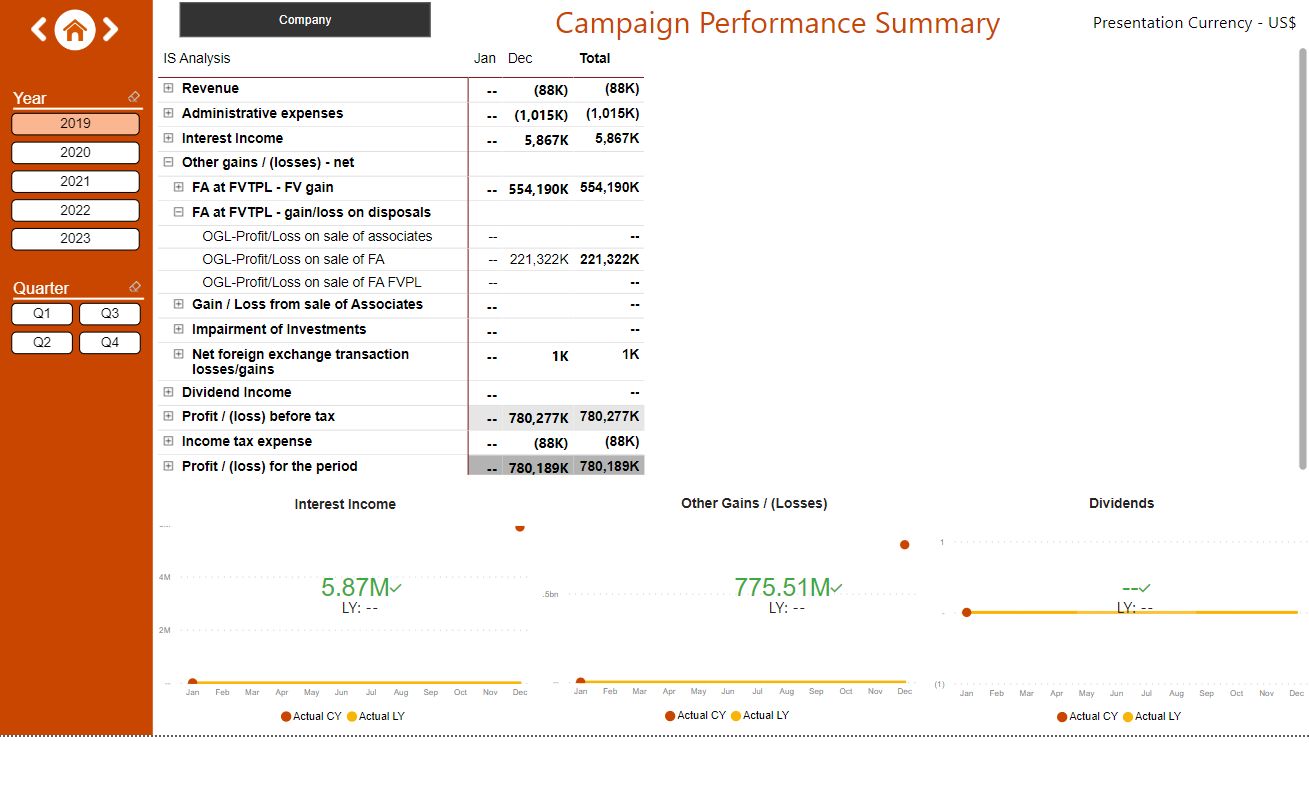
- Detailed break down of income statement to determine efficacy of campaign performance
- End-to-end Data Pipeline for user streaming data collection, storage and analysis from a mobile game
Section 2 - Sample Python scripts for data ingestion with Kinesis, preprocessing and loading to S3 with AWS Lambdas, workflow orchestration with Airflow DAG
As an example, the below script can be used to ingest our data into AWS Kinesis
import boto3
import json
# Initialize the Kinesis client outside of the function
kinesis_client = boto3.client('kinesis')
def send_data_to_kinesis(stream_name, data, partition_key):
try:
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key
)
except Exception as e:
# Handle exceptions (e.g., logging)
print(f"Error sending data to Kinesis: {e}")
# Example data ingestion
stream_name = 'game_data_stream'
data = {'event': 'new_session', 'user_id': '12345', 'timestamp': '2023-04-01T12:00:00'}
partition_key = str(data['user_id']) # Using user_id as the partition key for even distribution
send_data_to_kinesis(stream_name, data, partition_key)After the data is ingested, we can trigger an AWS Lambda function with Kinesis to preprocess (if needed) and load data to S3.
import boto3
import json
import base64
import csv
from io import StringIO
def lambda_handler(event, context):
s3_client = boto3.client('s3')
bucket_name = 'your-s3-bucket' # Replace with your actual bucket name
for record in event['Records']:
# Decode the data from Kinesis record
payload = json.loads(base64.b64decode(record['kinesis']['data']))
# Convert JSON to CSV
csv_data = json_to_csv(payload)
# Save to S3 as CSV
try:
s3_client.put_object(
Bucket=bucket_name,
Key=f'processed_data/{payload["user_id"]}.csv',
Body=csv_data
)
except Exception as e:
# Handle exceptions (e.g., logging)
print(f"Error processing or saving data: {e}")
def json_to_csv(data):
# Convert a flat JSON object to a CSV string
csv_buffer = StringIO()
writer = csv.writer(csv_buffer)
writer.writerow(data.keys()) # header row
writer.writerow(data.values()) # data row
return csv_buffer.getvalue()
def preprocess_data(data):
# Implement any data preprocessing logic here if needed
return dataWe can also handle multiple steps of the pipeline within a single Airflow DAG, which can also handle orchestration/scheduling as required.
# This is a sample DAG script showcasing one of the potential ways of automating the calculation of these metrics/aggregations in an end-to-end data pipeline setting. Only DAU, WAU, MAU metrics are used for this example. For full SQL queries of entire exercise, refer to the snowflake worksheet attachment
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeOperator
from astro.sql import transform
from astro import sql as aql
# Assumed to be the location of the sample kinesis function included in the presentation
from kinesis_utils import send_data_to_kinesis
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'game_data_etl',
default_args=default_args,
# Since we're including not only the Daily Active Users SQL query in this DAG, it may not be necessary to run the DAG daily. However, since this is just a proof of concept and I wanted to showcase multiple queries in 1 DAG along with the option to schedule, I chose to use the daily value for demo purposes.
schedule_interval='@daily',
catchup=False
)
# Ingest data from Kinesis to S3. We're assuming that the send_data_to_kinesis function is a separate script that should be imported appropriately. A sample code for this function was provided in the presentation.
def ingest_data():
# Assuming send_data_to_kinesis is defined elsewhere
data = {'event': 'new_session', 'user_id': '12345', 'timestamp': '2023-04-01T12:00:00'}
send_data_to_kinesis('game_data_stream', data)
# Load data from S3 to Snowflake. We're assuming that the data is in CSV format
load_data_sql = """
COPY INTO your_table
FROM 's3://{s3_bucket}/{s3_file_path}'
CREDENTIALS = (AWS_KEY_ID = 'your_aws_access_key_id' AWS_SECRET_KEY = 'your_aws_secret_access_key')
FILE_FORMAT = (TYPE = 'CSV' FIELD_DELIMITER = ',' SKIP_HEADER = 1);
"""
load_data_task = SnowflakeOperator(
task_id='load_data_from_s3_to_snowflake',
sql=load_data_sql,
snowflake_conn_id='your_snowflake_conn_id',
dag=dag
)
# Defining sample SQL queries for DAU, WAU, MAU. Refer to Snowflake_Worksheet.sql attachment for fully detailed SQL queries for the metrics/aggregations the technical task required, along with explanations.
dau_query = """
SELECT DATE(event_timestamp) AS date, COUNT(DISTINCT user_id) AS daily_active_users
FROM session_started
GROUP BY DATE(event_timestamp);
"""
wau_query = """
SELECT DATE_TRUNC('week', event_timestamp) AS week_start_date, COUNT(DISTINCT user_id) AS weekly_active_users
FROM session_started
GROUP BY DATE_TRUNC('week', event_timestamp);
"""
mau_query = """
SELECT DATE_TRUNC('month', event_timestamp) AS month_start_date, COUNT(DISTINCT user_id) AS monthly_active_users
FROM session_started
GROUP BY DATE_TRUNC('month', event_timestamp);
"""
# Tasks
ingest_task = PythonOperator(
task_id='ingest_data',
python_callable=ingest_data,
dag=dag
)
load_data_task = SnowflakeOperator(
task_id='load_data_from_s3_to_snowflake',
sql=load_data_sql,
snowflake_conn_id='your_snowflake_conn_id',
dag=dag
)
dau_task = aql.transform(
conn_id="snowflake_conn",
sql=dau_query,
task_id="calculate_dau",
dag=dag
)
wau_task = aql.transform(
conn_id="snowflake_conn",
sql=wau_query,
task_id="calculate_wau",
dag=dag
)
mau_task = aql.transform(
conn_id="snowflake_conn",
sql=mau_query,
task_id="calculate_mau",
dag=dag
)
# Setting up dependencies
ingest_task >> load_data_task
load_data_task >> [dau_task, wau_task, mau_task]For a massively multiplayer online game, we need a big variety of metrics and KPIs that will help the product development team to not only maximize profits and user retention, but also to identify pain points and improve player experience. These queries involve huge snowflake databases, so cost management and efficiency are of high importance. Other than ensuring we have correct clustering setup and optimized queries, we need to also ensure that we're not unnecessarily querying the entire database every time our reporting tools need to be updated, while maintaining a real-time stream of data.
To achieve this, we can use a mix of stored procedures/triggers/metadata timestamps techniques, depending on the database management system we're using. For the queries outlined below, this could be achieved for example by re-writing them as CTEs, and including a WHERE clause that compares system defined columns such as WHERE last_updated > (SELECT MAX(last_updated) FROM target_table)
--Active Users
-- Daily Active Users (DAU)
SELECT COUNT(DISTINCT USER_ID) AS active_users, --DISTINCT must be used to ensure users are only counted once per day regardless of how many times they log in
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
FROM LOGIN --We're selecting the distinct user_Ids as active users from the login table
GROUP BY date; --Grouping by days (which we defined earlier as date)
-- Monthly Active Users (MAU)
SELECT COUNT(DISTINCT USER_ID) AS active_users, --DISTINCT must be used to ensure users are only counted once per month regardless of how many times they log in
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month --We want to group by month so we're cutting the date from the event timestamp down to the start of the month
FROM LOGIN --We're selecting the distinct user_Ids as active users from the login table
GROUP BY month; --Grouping by months (which we defined earlier as month)
-- Weekly Active Users (WAU)
SELECT COUNT(DISTINCT USER_ID) AS active_users, --DISTINCT must be used to ensure users are only counted once per month regardless of how many times they log in
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week --We want to group by week so we're cutting the date from the event timestamp down to the start of the week
FROM LOGIN --We're selecting the distinct user_Ids as active users from the login table
GROUP BY week; --Grouping by weeks (which we defined earlier as week)
--New Users
-- Daily New Users
SELECT COUNT(DISTINCT USER_ID) AS new_users, --DISTINCT must be used to ensure new users are only counted once, in case for some reason the same user_id appears twice in the new_user table
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
FROM NEW_USER --This time we're selecting user.ids from the new user table and not the login table, as we care about new users not active users.
GROUP BY date; --Grouping by days (which we defined earlier as date)
-- Monthly New Users
SELECT COUNT(DISTINCT USER_ID) AS new_users, --DISTINCT must be used to ensure new users are only counted once, in case for some reason the same user_id appears twice in the new_user table
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month --We want to group by month so we're cutting the date from the event timestamp down to the start of each month
FROM NEW_USER --This time we're selecting user.ids from the new user table and not the login table, as we care about new users not active users.
GROUP BY month; --Grouping by months (which we defined earlier as month)
-- Weekly New Users
SELECT COUNT(DISTINCT USER_ID) AS new_users, --DISTINCT must be used to ensure new users are only counted once, in case for some reason the same user_id appears twice in the new_user table
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week --We want to group by week so we're cutting the date from the event timestamp down to the start of each week
FROM NEW_USER --This time we're selecting user.ids from the new user table and not the login table, as we care about new users not active users.
GROUP BY week; --Grouping by week (which we defined earlier as week)
--Revenue
-- Daily Revenue
SELECT SUM(USD_COST) AS revenue, --We use the sum function to sum up the USD cost column which we're assuming is the column that indicates the amount the user spent, in order to calculate total revenue
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting this data from the in app purchase log table as it contains the relevant info we need for this metric
GROUP BY date; --Grouping by day (which we defined earlier as date)
-- Monthly Revenue
SELECT SUM(USD_COST) AS revenue, --We use the sum function to sum up the USD cost column which we're assuming is the column that indicates the amount the user spent, in order to calculate total revenue
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month --We want to group by month so we're cutting the date from the event timestamp down to the start of each month
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting this data from the in app purchase log table as it contains the relevant info we need for this metric
GROUP BY month; --Grouping by month (which we defined earlier as month)
-- Weekly Revenue
SELECT SUM(USD_COST) AS revenue, --We use the sum function to sum up the USD cost column which we're assuming is the column that indicates the amount the user spent, in order to calculate total revenue
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week --We want to group by week so we're cutting the date from the event timestamp down to the start of each week
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting this data from the in app purchase log table as it contains the relevant info we need for this metric
GROUP BY week; --Grouping by week (which we defined earlier as week)
--Spenders (Buyers)
-- Daily Spenders
SELECT COUNT(DISTINCT USER_ID) AS spenders, --Since we want to count the number of spenders, and the same spender might appear more than once in the purchases table, we use the distinct clause on user_id
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting from the purchases table as that's where the spending information is
WHERE USD_COST > 0 --Again we're assuming this is the amount each user spent. Since we want spenders, this amount must be bigger than 0 to count as a spender
GROUP BY date; --Grouping by day (which we defined earlier as date)
-- Monthly Spenders
SELECT COUNT(DISTINCT USER_ID) AS spenders, --Since we want to count the number of spenders, and the same spender might appear more than once in the purchases table, we use the distinct clause on user_id
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month --We want to group by month so we're cutting the date from the event timestamp down to the start of each month
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting from the purchases table as that's where the spending information is
WHERE USD_COST > 0 --Again we're assuming this is the amount each user spent. Since we want spenders, this amount must be bigger than 0 to count as a spender
GROUP BY month; --Grouping by month (which we defined earlier as month)
-- Weekly Spenders
SELECT COUNT(DISTINCT USER_ID) AS spenders, --Since we want to count the number of spenders, and the same spender might appear more than once in the purchases table, we use the distinct clause on user_id
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week --We want to group by week so we're cutting the date from the event timestamp down to the start of each week
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting from the purchases table as that's where the spending information is
WHERE USD_COST > 0 --Again we're assuming this is the amount each user spent. Since we want spenders, this amount must be bigger than 0 to count as a spender
GROUP BY week; --Grouping by week (which we defined earlier as week)--ARPU (Average Revenue Per User)
-- Daily ARPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arpu, --To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date, --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
user_id AS USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
GROUP BY date, user_id; --Grouping by day (which we defined earlier as date) and user_id (here i forgot to use the name that i already defined earlier)
-- Monthly ARPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arpu, --To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month, --We want to group by month so we're cutting the date from the event timestamp down to the start of each month
user_id AS USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
GROUP BY month, user_id; --Grouping by month (which we defined earlier as month) and user_id (here i forgot to use the name that i already defined earlier)
-- Weekly ARPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arpu, --To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week, --We want to group by week so we're cutting the date from the event timestamp down to the start of each week
user_id AS USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
GROUP BY week, user_id; --Grouping by week (which we defined earlier as week) and user_id (here i forgot to use the name that i already defined earlier)
--ARPPU (Average Revenue Per Paying User)
-- Daily ARPPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arppu, --To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date, --We want to group by day so we're cutting the date from the event timestamp down to the start of each day
user_id AS PAYING_USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
WHERE USD_COST > 0 --We're defining paying user as any user that has made at least one purchase of over 0 usd
GROUP BY date, PAYING_USER; --Grouping by day (which we defined earlier as date) and user_id
-- Monthly ARPPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arppu,--To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month, --We want to group by month so we're cutting the date from the event timestamp down to the start of each month
user_id AS PAYING_USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
WHERE USD_COST > 0 --We're defining paying user as any user that has made at least one purchase of over 0 usd
GROUP BY month, PAYING_USER;; --Here I accidentally used a double semicolon. Grouping by month (which we defined earlier as month) and user_id
-- Weekly ARPPU
SELECT SUM(USD_COST) / COUNT(DISTINCT USER_ID) AS arppu,--To find the overall average revenue per user we must find the total revenue (sum(usd cost)) and divide it by the number of unique user_ids (Count(distinct userID)). If instead we want to see the average amount that each different user personally spends taking into account all their transactions in that period, we will use the AVG as ARPU instead
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week, --We want to group by week so we're cutting the date from the event timestamp down to the start of each week
user_id AS PAYING_USER --We also want to group by user and giving it a name here for easier readability of the query
FROM IN_APP_PURCHASE_LOG_SERVER --We're selecting the relevant info from the purchases table
WHERE USD_COST > 0 --We're defining paying user as any user that has made at least one purchase of over 0 usd
GROUP BY week, PAYING_USER; --Grouping by week (which we defined earlier as week) and user_id/*
1 Day, 3 Day, 7 Day Retention Rates
For the retetion rate queries, we're assuming that the retention rate definition is following a "Strict Next-Day Retention" rule. Meaning that a user is counted as retained for the 1 day rate only if they log in exactly the next day, but not if they log in the day after that. Users that log in 3 days later count towards the 3 day retention rate but not the 1 day retention rate, etc. If we were to define retention rate differently and assume that 1 day retention rate should include all users that login again within any 24 period after their registration, then the query would change to indicate WHEN DATE(L.EVENT_TIMESTAMP) <= DATE(NU.EVENT_TIMESTAMP) + INTERVAL '1 DAYT'... and so on. But this definition would create overlaps of users between each bucket. The users retained from day 1 would also count towards the 3 day retained rate etc, skewing results.
*/
--1 Day Retention Rate.
SELECT DATE(NU.EVENT_TIMESTAMP) AS Registration_Date, --We must use the date function to remove timestamp information from the dates we're comparing. We're taking registration date as the date from the new user table marked defined as NU
COUNT(DISTINCT CASE WHEN DATE(L.EVENT_TIMESTAMP) = DATE(NU.EVENT_TIMESTAMP) + INTERVAL '1 DAY' THEN L.USER_ID END) / COUNT(DISTINCT NU.USER_ID)::FLOAT AS One_Day_Retention_Rate --We're checking if the difference between the new user's registration and the new user's first login is 1 day. If yes, that user id is counted. If no, it returns null. Then we divide this number by all total new users to find the rate and we also convert to float to properly read the rate without truncating decimals.
FROM NEW_USER NU --Defining the new_user table as NU
LEFT JOIN LOGIN L ON NU.USER_ID = L.USER_ID --We're using a left join because we want to see all records from the new user table even if there's no matching record in the logins, because we must consider all new users to calculate retention rate, including those who didnt login again after registration.
WHERE DATE(L.EVENT_TIMESTAMP) BETWEEN DATE(NU.EVENT_TIMESTAMP) AND DATE(NU.EVENT_TIMESTAMP) + INTERVAL '1 DAY' --the login date from the login table should be within a 1 day interval since the registration date from the new user table
GROUP BY Registration_Date; --We group the results by registration date
--3 Day Retention Rate. Same logic as previous query, except we need the BETWEEN statement this time, to make sure the only users counted as retained are from the 3rd day only, but not after the 4th day or before the 3rd day.
SELECT DATE(NU.EVENT_TIMESTAMP) AS Registration_Date, --We must use the date function to remove timestamp information from the dates we're comparing. We're taking registration date as the date from the new user table marked defined as NU
COUNT(DISTINCT CASE WHEN DATE(L.EVENT_TIMESTAMP) BETWEEN DATE(NU.EVENT_TIMESTAMP) + INTERVAL '3 DAY' AND DATE(NU.EVENT_TIMESTAMP) + INTERVAL '4 DAY' THEN L.USER_ID END) / COUNT(DISTINCT NU.USER_ID)::FLOAT AS Three_Day_Retention_Rate --we need the BETWEEN statement this time, to make sure the only users counted as retained are from the 3rd day only, but not after the 4th day or before the 3rd day. If yes, that user id is counted. If no, it returns null. Then we divide this number by all total new users to find the rate and we also convert to float to properly read the rate without truncating decimals.
FROM NEW_USER NU --Defining the new_user table as NU
LEFT JOIN LOGIN L ON NU.USER_ID = L.USER_ID --We're using a left join because we want to see all records from the new user table even if there's no matching record in the logins, because we must consider all new users to calculate retention rate, including those who didnt login again after registration.
WHERE DATE(L.EVENT_TIMESTAMP) BETWEEN DATE(NU.EVENT_TIMESTAMP) AND DATE(NU.EVENT_TIMESTAMP) + INTERVAL '4 DAY' --Here I accidentally forgot to make sure that we should be filtering for logins specifically on 3rd day after registration, so before the AND we also need to add INTERVAL '3 DAY', like I did in the above distinct count
GROUP BY Registration_Date; --We group the results by registration date
--7 Day Retention Rate. Same logic as previous query. We need the BETWEEN statement again, to make sure the only users counted as retained are from the 7th day only, but not after the 8th day or before the 7th day.
SELECT DATE(NU.EVENT_TIMESTAMP) AS Registration_Date, --We must use the date function to remove timestamp information from the dates we're comparing. We're taking registration date as the date from the new user table marked defined as NU
COUNT(DISTINCT CASE WHEN DATE(L.EVENT_TIMESTAMP) BETWEEN DATE(NU.EVENT_TIMESTAMP) + INTERVAL '7 DAY' AND DATE(NU.EVENT_TIMESTAMP) + INTERVAL '8 DAY' THEN L.USER_ID END) / COUNT(DISTINCT NU.USER_ID)::FLOAT AS Seven_Day_Retention_Rate --we need the BETWEEN statement this time, to make sure the only users counted as retained are from the 3rd day only, but not after the 4th day or before the 3rd day. If yes, that user id is counted. If no, it returns null. Then we divide this number by all total new users to find the rate and we also convert to float to properly read the rate without truncating decimals.
FROM NEW_USER NU --Defining the new_user table as NU
LEFT JOIN LOGIN L ON NU.USER_ID = L.USER_ID --We're using a left join because we want to see all records from the new user table even if there's no matching record in the logins, because we must consider all new users to calculate retention rate, including those who didnt login again after registration.
WHERE DATE(L.EVENT_TIMESTAMP) BETWEEN DATE(NU.EVENT_TIMESTAMP) AND DATE(NU.EVENT_TIMESTAMP) + INTERVAL '8 DAY' --Again accidentally forgot to add the INTERVAL '7 DAY' part before AND
GROUP BY Registration_Date; --We group the results by registration date
--7 Day Conversion Rate, where conversion definition is assumed to be a user making any purchase within 7 days from their registration day
SELECT DATE_TRUNC('week', u.EVENT_TIMESTAMP) AS Registration_Week, --We use the date_trunc function cut the date down to the start of each week since we want weekly conversion rates
COUNT(DISTINCT u.USER_ID) AS Total_New_Users,
COUNT(DISTINCT CASE
WHEN p.EVENT_TIMESTAMP <= u.EVENT_TIMESTAMP + INTERVAL '7 days' THEN p.USER_ID --If the purchase was made within 7 days or less from registration, then count it as converted, else null
ELSE NULL
END) AS Users_Converted_Within_7_Days,
COUNT(DISTINCT CASE --If the purchase was made within 7 days or less from registration then count it and divide with total distinct users to get the conversion rate
WHEN p.EVENT_TIMESTAMP <= u.EVENT_TIMESTAMP + INTERVAL '7 days' THEN p.USER_ID
ELSE NULL
END)::FLOAT / COUNT(DISTINCT u.USER_ID) AS Seven_Day_Conversion_Rate --We only need to type cast just one of the 2 numbers involved in the division as float, and because of implicit type conversion the result will be float too even if the other number was an integer.
FROM NEW_USER u
LEFT JOIN IN_APP_PURCHASE_LOG_SERVER p ON u.USER_ID = p.USER_ID --Here we use a left join because we want to make sure that all new users (u.USER_ID) are included in the analysis even if they didn't make a purchase
GROUP BY DATE_TRUNC('week', u.EVENT_TIMESTAMP) --In some database systems we might not be able to use the alias we defined next to the group by clause is because even though we write it at the end, it is actually evaluated before the select clause. But in more modern ones like postgresql and snowflake, you can use the alias anyway.
ORDER BY Registration_Week;--Ships Owned By Every User Every Day. Amount of ships owned should be amount bought (SC<0) minus amount sold(SC>0) and not simply amount of ships bought.
SELECT EVENT_TIMESTAMP::date AS date, --We're typecasting the datetime timestamp into just date. We can also use the date function instead of :: but I just wanted to showcase a different way to write it
USER_ID,
COUNT(DISTINCT CASE WHEN SC_AMOUNT < 0 THEN SHIP_ID END) - COUNT(DISTINCT CASE WHEN SC_AMOUNT > 0 THEN SHIP_ID END) AS unique_ships_owned --Ships ownwed is count of amount bought (SC<0) ship_ids minus count of amount sold (SC>0) ship_ids
FROM SHIP_TRANSACTION_LOG
GROUP BY date, USER_ID;
--Daily Ships Popularity. Here we're counting the number of users owning a particular ship on each given day, and ordering the list in descending order so that the most popular ship is at the top. Again, the most "popular" ships is assumed to be the one that the most users currently own, and not the one that is most bought. The rationale is that a ship that is bought 1000 times but then sold immediately 900 times should not be considered more popular than a ship that was bought 500 times but never sold.
SELECT EVENT_TIMESTAMP::date AS date,
SHIP_ID,
COUNT(DISTINCT CASE WHEN SC_AMOUNT < 0 THEN USER_ID END) - COUNT(DISTINCT CASE WHEN SC_AMOUNT > 0 THEN USER_ID END) AS users_owning_ship
FROM SHIP_TRANSACTION_LOG
GROUP BY date, SHIP_ID
ORDER BY users_owning_ship DESC;--Amount of Battles, Logins, Days Since Registration Before First Purchase.
--To write this query in a clean and optimized way, first we will define a common table expression to find the date of the first purchase per user
WITH FirstPurchase AS (
SELECT USER_ID,
MIN(EVENT_TIMESTAMP) AS FirstPurchaseDate --Minimum date of purchase per user, indicating their first purchase
FROM IN_APP_PURCHASE_LOG_SERVER
GROUP BY USER_ID
),
--We then define another CTE to count number of battles each user participated in before their first purchase
BattlesBeforePurchase AS (
SELECT fp.USER_ID,
COUNT(*) AS BattlesBeforeFirstPurchase
FROM FirstPurchase fp
JOIN MULTIPLAYER_BATTLE_STARTED mbs ON fp.USER_ID = mbs.USER_ID
WHERE mbs.EVENT_TIMESTAMP < fp.FirstPurchaseDate -- Only consider battles that occurred before the first purchase
GROUP BY fp.USER_ID
),
--Same logic as above but for logins
LoginsBeforePurchase AS (
SELECT fp.USER_ID,
COUNT(*) AS LoginsBeforeFirstPurchase
FROM FirstPurchase fp
JOIN LOGIN l ON fp.USER_ID = l.USER_ID
WHERE l.EVENT_TIMESTAMP < fp.FirstPurchaseDate
GROUP BY fp.USER_ID
),
--Same logic as above but instead of counting number of X event, we're counting days since registration.
DaysSinceRegistration AS (
SELECT fp.USER_ID,
DATEDIFF(day, nu.EVENT_TIMESTAMP, fp.FirstPurchaseDate) AS DaysSinceRegistrationBeforeFirstPurchase
FROM FirstPurchase fp
JOIN NEW_USER nu ON fp.USER_ID = nu.USER_ID
)
--This final section of the query combines the data from the above CTEs for each user. Since we're using LEFT JOINS to combine the data, there is the possibility of nulls. I chose to use COALESCE to handle users with 0 battles/logins/days before first purchase and get rid of null values that could possibly interfere with downstream analysis.
SELECT fp.USER_ID,
COALESCE(bbp.BattlesBeforeFirstPurchase, 0) AS BattlesBeforeFirstPurchase,
COALESCE(lbp.LoginsBeforeFirstPurchase, 0) AS LoginsBeforeFirstPurchase,
COALESCE(dsr.DaysSinceRegistrationBeforeFirstPurchase, 0) AS DaysSinceRegistrationBeforeFirstPurchase
FROM FirstPurchase fp
LEFT JOIN BattlesBeforePurchase bbp ON fp.USER_ID = bbp.USER_ID
LEFT JOIN LoginsBeforePurchase lbp ON fp.USER_ID = lbp.USER_ID
LEFT JOIN DaysSinceRegistration dsr ON fp.USER_ID = dsr.USER_ID;--Daily/Weekly/Monthly Revenue per User.
-- Daily Revenue per User
SELECT SUM(USD_COST) AS revenue_per_user,
DATE_TRUNC('day', EVENT_TIMESTAMP) AS date,
user_id
FROM IN_APP_PURCHASE_LOG_SERVER
GROUP BY date, user_id;
-- Weekly Revenue per User
SELECT SUM(USD_COST) AS revenue_per_user,
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week,
user_id
FROM IN_APP_PURCHASE_LOG_SERVER
GROUP BY week, user_id;
-- Monthly Revenue per User
SELECT SUM(USD_COST) AS revenue_per_user,
DATE_TRUNC('month', EVENT_TIMESTAMP) AS month,
user_id
FROM IN_APP_PURCHASE_LOG_SERVER
GROUP BY month, user_id;--New Users Participation in Battles (1/3/7/14 Days Since Registration):
-- 1 Day Since Registration
SELECT COUNT(DISTINCT b.USER_ID) AS new_users_battles,
DATE_TRUNC('week', b.EVENT_TIMESTAMP) AS week
FROM MULTIPLAYER_BATTLE_STARTED b
JOIN NEW_USER n ON b.USER_ID = n.USER_ID
AND DATE_TRUNC('day', b.EVENT_TIMESTAMP) <= DATE_TRUNC('day', n.EVENT_TIMESTAMP) + INTERVAL '1 day'
AND b.EVENT_TIMESTAMP >= n.EVENT_TIMESTAMP
GROUP BY week;
-- 3 Days Since Registration
SELECT COUNT(DISTINCT b.USER_ID) AS new_users_battles,
DATE_TRUNC('week', b.EVENT_TIMESTAMP) AS week
FROM MULTIPLAYER_BATTLE_STARTED b
JOIN NEW_USER n ON b.USER_ID = n.USER_ID
AND DATE_TRUNC('day', b.EVENT_TIMESTAMP) <= DATE_TRUNC('day', n.EVENT_TIMESTAMP) + INTERVAL '3 days'
AND b.EVENT_TIMESTAMP >= n.EVENT_TIMESTAMP
GROUP BY week;
-- 7 Days Since Registration
SELECT COUNT(DISTINCT b.USER_ID) AS new_users_battles,
DATE_TRUNC('week', b.EVENT_TIMESTAMP) AS week
FROM MULTIPLAYER_BATTLE_STARTED b
JOIN NEW_USER n ON b.USER_ID = n.USER_ID
AND DATE_TRUNC('day', b.EVENT_TIMESTAMP) <= DATE_TRUNC('day', n.EVENT_TIMESTAMP) + INTERVAL '7 days'
AND b.EVENT_TIMESTAMP >= n.EVENT_TIMESTAMP
GROUP BY week;
-- 14 Days Since Registration
SELECT COUNT(DISTINCT b.USER_ID) AS new_users_battles,
DATE_TRUNC('week', b.EVENT_TIMESTAMP) AS week
FROM MULTIPLAYER_BATTLE_STARTED b
JOIN NEW_USER n ON b.USER_ID = n.USER_ID
AND DATE_TRUNC('day', b.EVENT_TIMESTAMP) <= DATE_TRUNC('day', n.EVENT_TIMESTAMP) + INTERVAL '14 days'
AND b.EVENT_TIMESTAMP >= n.EVENT_TIMESTAMP
GROUP BY week;
--Battle Participation by Active Users. Assumed that what the exercise wanted is weekly battle participation by active users, as no timeframe was specified:
SELECT COUNT(*) AS active_users_battles,
DATE_TRUNC('week', EVENT_TIMESTAMP) AS week
FROM MULTIPLAYER_BATTLE_STARTED
WHERE USER_ID IN (SELECT USER_ID FROM LOGIN)
GROUP BY week;