diff --git a/.github/workflows/api_inference_build_documentation.yml b/.github/workflows/api_inference_build_documentation.yml
new file mode 100644
index 000000000..58afc1abb
--- /dev/null
+++ b/.github/workflows/api_inference_build_documentation.yml
@@ -0,0 +1,20 @@
+name: Build api-inference documentation
+
+on:
+ push:
+ paths:
+ - "docs/api-inference/**"
+ branches:
+ - main
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
+ with:
+ commit_sha: ${{ github.sha }}
+ package: hub-docs
+ package_name: api-inference
+ path_to_docs: hub-docs/docs/api-inference/
+ additional_args: --not_python_module
+ secrets:
+ token: ${{ secrets.HUGGINGFACE_PUSH }}
diff --git a/.github/workflows/api_inference_build_pr_documentation.yml b/.github/workflows/api_inference_build_pr_documentation.yml
new file mode 100644
index 000000000..8fbe16653
--- /dev/null
+++ b/.github/workflows/api_inference_build_pr_documentation.yml
@@ -0,0 +1,21 @@
+name: Build api-inference PR Documentation
+
+on:
+ pull_request:
+ paths:
+ - "docs/api-inference/**"
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
+ cancel-in-progress: true
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
+ with:
+ commit_sha: ${{ github.event.pull_request.head.sha }}
+ pr_number: ${{ github.event.number }}
+ package: hub-docs
+ package_name: api-inference
+ path_to_docs: hub-docs/docs/api-inference/
+ additional_args: --not_python_module
diff --git a/.github/workflows/api_inference_delete_doc_comment.yml b/.github/workflows/api_inference_delete_doc_comment.yml
new file mode 100644
index 000000000..54e26aaad
--- /dev/null
+++ b/.github/workflows/api_inference_delete_doc_comment.yml
@@ -0,0 +1,15 @@
+name: Delete api-inference dev documentation
+
+on:
+ pull_request:
+ types: [ closed ]
+
+
+jobs:
+ delete:
+ uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
+ with:
+ pr_number: ${{ github.event.number }}
+ package: hub-docs
+ package_name: api-inference
+
diff --git a/docs/api-inference/_toctree.yml b/docs/api-inference/_toctree.yml
new file mode 100644
index 000000000..4ad35f322
--- /dev/null
+++ b/docs/api-inference/_toctree.yml
@@ -0,0 +1,14 @@
+- sections:
+ - local: index
+ title: 🤗 Accelerated Inference API
+ - local: quicktour
+ title: Overview
+ - local: detailed_parameters
+ title: Detailed parameters
+ - local: parallelism
+ title: Parallelism and batch jobs
+ - local: usage
+ title: Detailed usage and pinned models
+ - local: faq
+ title: More information about the API
+ title: Getting started
diff --git a/docs/api-inference/detailed_parameters.mdx b/docs/api-inference/detailed_parameters.mdx
new file mode 100644
index 000000000..ebeda920f
--- /dev/null
+++ b/docs/api-inference/detailed_parameters.mdx
@@ -0,0 +1,1277 @@
+# Detailed parameters
+
+## Which task is used by this model ?
+
+In general the 🤗 Hosted API Inference accepts a simple string as an
+input. However, more advanced usage depends on the "task" that the
+model solves.
+
+The "task" of a model is defined here on it's model page:
+
+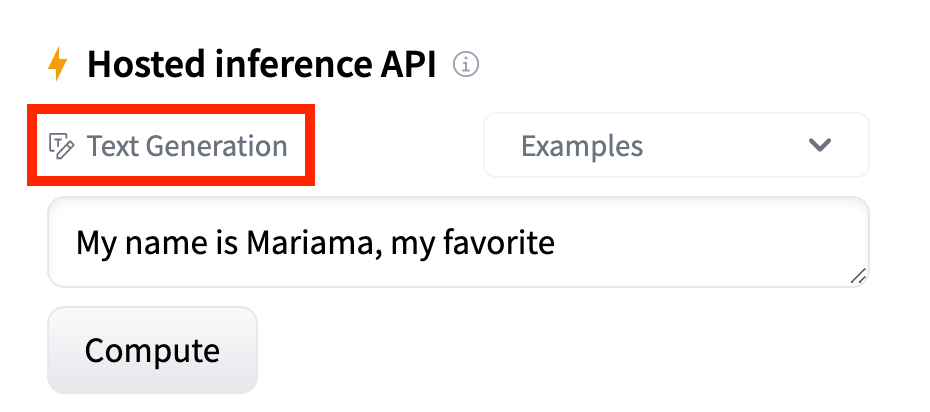 +
+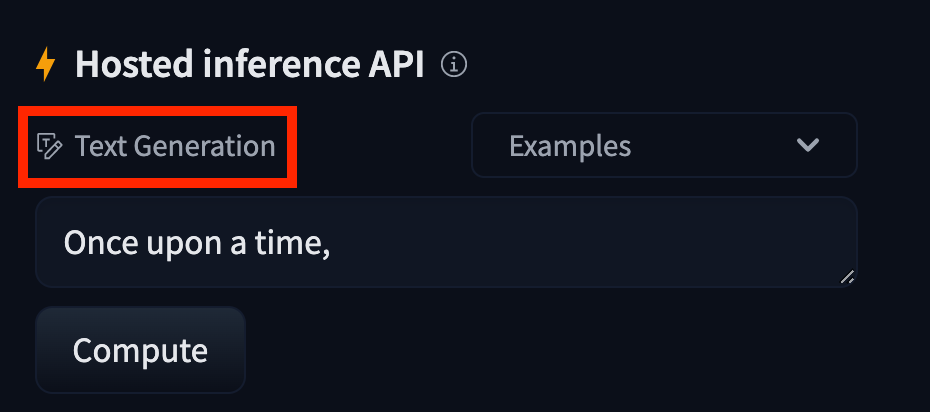 +
+## Natural Language Processing
+
+### Fill Mask task
+
+Tries to fill in a hole with a missing word (token to be precise).
+That's the base task for BERT models.
+
+
+
+**Recommended model**:
+[bert-base-uncased](https://huggingface.co/bert-base-uncased) (it's a simple model, but fun to play with).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START fill_mask_inference",
+"end-before": "END fill_mask_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_fill_mask_inference",
+"end-before": "END node_fill_mask_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_fill_mask_inference",
+"end-before": "END curl_fill_mask_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required): | a string to be filled from, must contain the [MASK] token (check model card for exact name of the mask) |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START fill_mask_inference_answer",
+"end-before": "END fill_mask_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------------------------------ |
+| **sequence** | The actual sequence of tokens that ran against the model (may contain special tokens) |
+| **score** | The probability for this token. |
+| **token** | The id of the token |
+| **token_str** | The string representation of the token |
+
+### Summarization task
+
+This task is well known to summarize longer text into shorter text.
+Be careful, some models have a maximum length of input. That means that
+the summary cannot handle full books for instance. Be careful when
+choosing your model. If you want to discuss your summarization needs,
+please get in touch with us:
+
+
+
+**Recommended model**:
+[facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START summarization_inference",
+"end-before": "END summarization_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_summarization_inference",
+"end-before": "END node_summarization_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_summarization_inference",
+"end-before": "END curl_summarization_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be summarized |
+| **parameters** | a dict containing the following keys: |
+| min_length | (Default: `None`). Integer to define the minimum length **in tokens** of the output summary. |
+| max_length | (Default: `None`). Integer to define the maximum length **in tokens** of the output summary. |
+| top_k | (Default: `None`). Integer to define the top tokens considered within the `sample` operation to create new text. |
+| top_p | (Default: `None`). Float to define the tokens that are within the `sample` operation of text generation. Add tokens in the sample for more probable to least probable until the sum of the probabilities is greater than `top_p`. |
+| temperature | (Default: `1.0`). Float (0.0-100.0). The temperature of the sampling operation. 1 means regular sampling, `0` means always take the highest score, `100.0` is getting closer to uniform probability. |
+| repetition_penalty | (Default: `None`). Float (0.0-100.0). The more a token is used within generation the more it is penalized to not be picked in successive generation passes. |
+| max_time | (Default: `None`). Float (0-120.0). The amount of time in seconds that the query should take maximum. Network can cause some overhead so it will be a soft limit. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+| Returned values | |
+| :--------------------- | :----------------------------- |
+| **summarization_text** | The string after summarization |
+
+### Question Answering task
+
+Want to have a nice know-it-all bot that can answer any question?
+
+
+
+**Recommended model**:
+[deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2).
+
+
+
+Available with: [🤗Transformers](https://github.com/huggingface/transformers) and
+[AllenNLP](https://github.com/allenai/allennlp)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START question_answering_inference",
+"end-before": "END question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_question_answering_inference",
+"end-before": "END node_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_question_answering_inference",
+"end-before": "END curl_question_answering_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+Return value is a dict.
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START question_answering_inference_answer",
+"end-before": "END question_answering_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------------- |
+| **answer** | A string that’s the answer within the text. |
+| **score** | A float that represents how likely that the answer is correct |
+| **start** | The index (string wise) of the start of the answer within `context`. |
+| **stop** | The index (string wise) of the stop of the answer within `context`. |
+
+### Table Question Answering task
+
+Don't know SQL? Don't want to dive into a large spreadsheet? Ask
+questions in plain english!
+
+
+
+**Recommended model**:
+[google/tapas-base-finetuned-wtq](https://huggingface.co/google/tapas-base-finetuned-wtq).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START table_question_answering_inference",
+"end-before": "END table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_table_question_answering_inference",
+"end-before": "END node_table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_table_question_answering_inference",
+"end-before": "END curl_table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | |
+| query (required) | The query in plain text that you want to ask the table |
+| table (required) | A table of data represented as a dict of list where entries are headers and the lists are all the values, all lists must have the same size. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START table_question_answering_inference_answer",
+"end-before": "END table_question_answering_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :---------------------------------------------------------- |
+| **answer** | The plaintext answer |
+| **coordinates** | a list of coordinates of the cells referenced in the answer |
+| **cells** | a list of coordinates of the cells contents |
+| **aggregator** | The aggregator used to get the answer |
+
+### Sentence Similarity task
+
+Calculate the semantic similarity between one text and a list of other sentences by comparing their embeddings.
+
+
+
+**Recommended model**:
+[sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2).
+
+
+
+Available with: [Sentence Transformers](https://www.sbert.net/index.html)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START sentence_similarity_inference",
+"end-before": "END sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_sentence_similarity_inference",
+"end-before": "END node_sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_sentence_similarity_inference",
+"end-before": "END curl_sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | |
+| source_sentence (required) | The string that you wish to compare the other strings with. This can be a phrase, sentence, or longer passage, depending on the model being used. |
+| sentences (required) | A list of strings which will be compared against the source_sentence. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+The return value is a list of similarity scores, given as floats.
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START sentence_similarity_inference_answer",
+"end-before": "END sentence_similarity_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------ |
+| **Scores** | The associated similarity score for each of the given strings |
+
+### Text Classification task
+
+Usually used for sentiment-analysis this will output the likelihood of
+classes of an input.
+
+
+
+**Recommended model**:
+[distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_classification_inference",
+"end-before": "END text_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_text_classification_inference",
+"end-before": "END node_text_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_text_classification_inference",
+"end-before": "END curl_text_classification_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be classified |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_classification_inference_answer",
+"end-before": "END text_classification_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :--------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) |
+| **score** | A floats that represents how likely is that the text belongs the this class. |
+
+### Text Generation task
+
+Use to continue text from a prompt. This is a very generic task.
+
+
+
+**Recommended model**: [gpt2](https://huggingface.co/gpt2) (it's a simple model, but fun to play with).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_generation_inference",
+"end-before": "END text_generation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_text_generation_inference",
+"end-before": "END node_text_generation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_text_generation_inference",
+"end-before": "END curl_text_generation_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required): | a string to be generated from |
+| **parameters** | dict containing the following keys: |
+| top_k | (Default: `None`). Integer to define the top tokens considered within the `sample` operation to create new text. |
+| top_p | (Default: `None`). Float to define the tokens that are within the `sample` operation of text generation. Add tokens in the sample for more probable to least probable until the sum of the probabilities is greater than `top_p`. |
+| temperature | (Default: `1.0`). Float (0.0-100.0). The temperature of the sampling operation. 1 means regular sampling, `0` means always take the highest score, `100.0` is getting closer to uniform probability. |
+| repetition_penalty | (Default: `None`). Float (0.0-100.0). The more a token is used within generation the more it is penalized to not be picked in successive generation passes. |
+| max_new_tokens | (Default: `None`). Int (0-250). The amount of new tokens to be generated, this does **not** include the input length it is a estimate of the size of generated text you want. Each new tokens slows down the request, so look for balance between response times and length of text generated. |
+| max_time | (Default: `None`). Float (0-120.0). The amount of time in seconds that the query should take maximum. Network can cause some overhead so it will be a soft limit. Use that in combination with `max_new_tokens` for best results. |
+| return_full_text | (Default: `True`). Bool. If set to False, the return results will **not** contain the original query making it easier for prompting. |
+| num_return_sequences | (Default: `1`). Integer. The number of proposition you want to be returned. |
+| do_sample | (Optional: `True`). Bool. Whether or not to use sampling, use greedy decoding otherwise. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_generation_inference_answer",
+"end-before": "END text_generation_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :----------------- | :--------------------- |
+| **generated_text** | The continuated string |
+
+### Text2Text Generation task
+
+Essentially [Text-generation task](#text-generation-task). But uses
+Encoder-Decoder architecture, so might change in the future for more
+options.
+
+### Token Classification task
+
+Usually used for sentence parsing, either grammatical, or Named Entity
+Recognition (NER) to understand keywords contained within text.
+
+
+
+**Recommended model**:
+[dbmdz/bert-large-cased-finetuned-conll03-english](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english)
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers),
+[Flair](https://github.com/flairNLP/flair)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START token_classification_inference",
+"end-before": "END token_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_token_classification_inference",
+"end-before": "END node_token_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_token_classification_inference",
+"end-before": "END curl_token_classification_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be classified |
+| **parameters** | a dict containing the following key: |
+| aggregation_strategy | (Default: `simple`). There are several aggregation strategies:
+
+## Natural Language Processing
+
+### Fill Mask task
+
+Tries to fill in a hole with a missing word (token to be precise).
+That's the base task for BERT models.
+
+
+
+**Recommended model**:
+[bert-base-uncased](https://huggingface.co/bert-base-uncased) (it's a simple model, but fun to play with).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START fill_mask_inference",
+"end-before": "END fill_mask_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_fill_mask_inference",
+"end-before": "END node_fill_mask_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_fill_mask_inference",
+"end-before": "END curl_fill_mask_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required): | a string to be filled from, must contain the [MASK] token (check model card for exact name of the mask) |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START fill_mask_inference_answer",
+"end-before": "END fill_mask_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------------------------------ |
+| **sequence** | The actual sequence of tokens that ran against the model (may contain special tokens) |
+| **score** | The probability for this token. |
+| **token** | The id of the token |
+| **token_str** | The string representation of the token |
+
+### Summarization task
+
+This task is well known to summarize longer text into shorter text.
+Be careful, some models have a maximum length of input. That means that
+the summary cannot handle full books for instance. Be careful when
+choosing your model. If you want to discuss your summarization needs,
+please get in touch with us:
+
+
+
+**Recommended model**:
+[facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START summarization_inference",
+"end-before": "END summarization_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_summarization_inference",
+"end-before": "END node_summarization_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_summarization_inference",
+"end-before": "END curl_summarization_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be summarized |
+| **parameters** | a dict containing the following keys: |
+| min_length | (Default: `None`). Integer to define the minimum length **in tokens** of the output summary. |
+| max_length | (Default: `None`). Integer to define the maximum length **in tokens** of the output summary. |
+| top_k | (Default: `None`). Integer to define the top tokens considered within the `sample` operation to create new text. |
+| top_p | (Default: `None`). Float to define the tokens that are within the `sample` operation of text generation. Add tokens in the sample for more probable to least probable until the sum of the probabilities is greater than `top_p`. |
+| temperature | (Default: `1.0`). Float (0.0-100.0). The temperature of the sampling operation. 1 means regular sampling, `0` means always take the highest score, `100.0` is getting closer to uniform probability. |
+| repetition_penalty | (Default: `None`). Float (0.0-100.0). The more a token is used within generation the more it is penalized to not be picked in successive generation passes. |
+| max_time | (Default: `None`). Float (0-120.0). The amount of time in seconds that the query should take maximum. Network can cause some overhead so it will be a soft limit. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+| Returned values | |
+| :--------------------- | :----------------------------- |
+| **summarization_text** | The string after summarization |
+
+### Question Answering task
+
+Want to have a nice know-it-all bot that can answer any question?
+
+
+
+**Recommended model**:
+[deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2).
+
+
+
+Available with: [🤗Transformers](https://github.com/huggingface/transformers) and
+[AllenNLP](https://github.com/allenai/allennlp)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START question_answering_inference",
+"end-before": "END question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_question_answering_inference",
+"end-before": "END node_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_question_answering_inference",
+"end-before": "END curl_question_answering_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+Return value is a dict.
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START question_answering_inference_answer",
+"end-before": "END question_answering_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------------- |
+| **answer** | A string that’s the answer within the text. |
+| **score** | A float that represents how likely that the answer is correct |
+| **start** | The index (string wise) of the start of the answer within `context`. |
+| **stop** | The index (string wise) of the stop of the answer within `context`. |
+
+### Table Question Answering task
+
+Don't know SQL? Don't want to dive into a large spreadsheet? Ask
+questions in plain english!
+
+
+
+**Recommended model**:
+[google/tapas-base-finetuned-wtq](https://huggingface.co/google/tapas-base-finetuned-wtq).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START table_question_answering_inference",
+"end-before": "END table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_table_question_answering_inference",
+"end-before": "END node_table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_table_question_answering_inference",
+"end-before": "END curl_table_question_answering_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | |
+| query (required) | The query in plain text that you want to ask the table |
+| table (required) | A table of data represented as a dict of list where entries are headers and the lists are all the values, all lists must have the same size. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START table_question_answering_inference_answer",
+"end-before": "END table_question_answering_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :---------------------------------------------------------- |
+| **answer** | The plaintext answer |
+| **coordinates** | a list of coordinates of the cells referenced in the answer |
+| **cells** | a list of coordinates of the cells contents |
+| **aggregator** | The aggregator used to get the answer |
+
+### Sentence Similarity task
+
+Calculate the semantic similarity between one text and a list of other sentences by comparing their embeddings.
+
+
+
+**Recommended model**:
+[sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2).
+
+
+
+Available with: [Sentence Transformers](https://www.sbert.net/index.html)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START sentence_similarity_inference",
+"end-before": "END sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_sentence_similarity_inference",
+"end-before": "END node_sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_sentence_similarity_inference",
+"end-before": "END curl_sentence_similarity_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | |
+| source_sentence (required) | The string that you wish to compare the other strings with. This can be a phrase, sentence, or longer passage, depending on the model being used. |
+| sentences (required) | A list of strings which will be compared against the source_sentence. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+The return value is a list of similarity scores, given as floats.
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START sentence_similarity_inference_answer",
+"end-before": "END sentence_similarity_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :------------------------------------------------------------ |
+| **Scores** | The associated similarity score for each of the given strings |
+
+### Text Classification task
+
+Usually used for sentiment-analysis this will output the likelihood of
+classes of an input.
+
+
+
+**Recommended model**:
+[distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_classification_inference",
+"end-before": "END text_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_text_classification_inference",
+"end-before": "END node_text_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_text_classification_inference",
+"end-before": "END curl_text_classification_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be classified |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_classification_inference_answer",
+"end-before": "END text_classification_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :--------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) |
+| **score** | A floats that represents how likely is that the text belongs the this class. |
+
+### Text Generation task
+
+Use to continue text from a prompt. This is a very generic task.
+
+
+
+**Recommended model**: [gpt2](https://huggingface.co/gpt2) (it's a simple model, but fun to play with).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_generation_inference",
+"end-before": "END text_generation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_text_generation_inference",
+"end-before": "END node_text_generation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_text_generation_inference",
+"end-before": "END curl_text_generation_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required): | a string to be generated from |
+| **parameters** | dict containing the following keys: |
+| top_k | (Default: `None`). Integer to define the top tokens considered within the `sample` operation to create new text. |
+| top_p | (Default: `None`). Float to define the tokens that are within the `sample` operation of text generation. Add tokens in the sample for more probable to least probable until the sum of the probabilities is greater than `top_p`. |
+| temperature | (Default: `1.0`). Float (0.0-100.0). The temperature of the sampling operation. 1 means regular sampling, `0` means always take the highest score, `100.0` is getting closer to uniform probability. |
+| repetition_penalty | (Default: `None`). Float (0.0-100.0). The more a token is used within generation the more it is penalized to not be picked in successive generation passes. |
+| max_new_tokens | (Default: `None`). Int (0-250). The amount of new tokens to be generated, this does **not** include the input length it is a estimate of the size of generated text you want. Each new tokens slows down the request, so look for balance between response times and length of text generated. |
+| max_time | (Default: `None`). Float (0-120.0). The amount of time in seconds that the query should take maximum. Network can cause some overhead so it will be a soft limit. Use that in combination with `max_new_tokens` for best results. |
+| return_full_text | (Default: `True`). Bool. If set to False, the return results will **not** contain the original query making it easier for prompting. |
+| num_return_sequences | (Default: `1`). Integer. The number of proposition you want to be returned. |
+| do_sample | (Optional: `True`). Bool. Whether or not to use sampling, use greedy decoding otherwise. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START text_generation_inference_answer",
+"end-before": "END text_generation_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :----------------- | :--------------------- |
+| **generated_text** | The continuated string |
+
+### Text2Text Generation task
+
+Essentially [Text-generation task](#text-generation-task). But uses
+Encoder-Decoder architecture, so might change in the future for more
+options.
+
+### Token Classification task
+
+Usually used for sentence parsing, either grammatical, or Named Entity
+Recognition (NER) to understand keywords contained within text.
+
+
+
+**Recommended model**:
+[dbmdz/bert-large-cased-finetuned-conll03-english](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english)
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers),
+[Flair](https://github.com/flairNLP/flair)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START token_classification_inference",
+"end-before": "END token_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_token_classification_inference",
+"end-before": "END node_token_classification_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_token_classification_inference",
+"end-before": "END curl_token_classification_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be classified |
+| **parameters** | a dict containing the following key: |
+| aggregation_strategy | (Default: `simple`). There are several aggregation strategies:
`none`: Every token gets classified without further aggregation.
`simple`: Entities are grouped according to the default schema (B-, I- tags get merged when the tag is similar).
`first`: Same as the `simple` strategy except words cannot end up with different tags. Words will use the tag of the first token when there is ambiguity.
`average`: Same as the `simple` strategy except words cannot end up with different tags. Scores are averaged across tokens and then the maximum label is applied.
`max`: Same as the `simple` strategy except words cannot end up with different tags. Word entity will be the token with the maximum score. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START token_classification_inference_answer",
+"end-before": "END token_classification_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :--------------- | :--------------------------------------------------------------------------------------------------------- |
+| **entity_group** | The type for the entity being recognized (model specific). |
+| **score** | How likely the entity was recognized. |
+| **word** | The string that was captured |
+| **start** | The offset stringwise where the answer is located. Useful to disambiguate if `word` occurs multiple times. |
+| **end** | The offset stringwise where the answer is located. Useful to disambiguate if `word` occurs multiple times. |
+
+### Named Entity Recognition (NER) task
+
+See [Token-classification task](#token-classification-task)
+
+### Translation task
+
+This task is well known to translate text from one language to another
+
+
+
+**Recommended model**:
+[Helsinki-NLP/opus-mt-ru-en](https://huggingface.co/Helsinki-NLP/opus-mt-ru-en).
+Helsinki-NLP uploaded many models with many language pairs.
+**Recommended model**: [t5-base](https://huggingface.co/t5-base).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START translation_inference",
+"end-before": "END translation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_translation_inference",
+"end-before": "END node_translation_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_translation_inference",
+"end-before": "END curl_translation_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string to be translated in the original languages |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+| Returned values | |
+| :------------------- | :--------------------------- |
+| **translation_text** | The string after translation |
+
+### Zero-Shot Classification task
+
+This task is super useful to try out classification with zero code,
+you simply pass a sentence/paragraph and the possible labels for that
+sentence, and you get a result.
+
+
+
+**Recommended model**:
+[facebook/bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START zero_shot_inference",
+"end-before": "END zero_shot_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_zero_shot_inference",
+"end-before": "END node_zero_shot_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_zero_shot_inference",
+"end-before": "END curl_zero_shot_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | a string or list of strings |
+| **parameters** (required) | a dict containing the following keys: |
+| candidate_labels (required) | a list of strings that are potential classes for `inputs`. (max 10 candidate_labels, for more, simply run multiple requests, results are going to be misleading if using too many candidate_labels anyway. If you want to keep the exact same, you can simply run `multi_label=True` and do the scaling on your end. ) |
+| multi_label | (Default: `false`) Boolean that is set to True if classes can overlap |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+Response:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START zero_shot_inference_answer",
+"end-before": "END zero_shot_inference_answer",
+"dedent": 8}
+
+
+
+
+| Returned values | |
+| :-------------- | :-------------------------------------------------------------------------------------------- |
+| **sequence** | The string sent as an input |
+| **labels** | The list of strings for labels that you sent (in order) |
+| **scores** | a list of floats that correspond the the probability of label, in the same order as `labels`. |
+
+### Conversational task
+
+This task corresponds to any chatbot like structure. Models tend to have
+shorter max_length, so please check with caution when using a given
+model if you need long range dependency or not.
+
+
+
+**Recommended model**:
+[microsoft/DialoGPT-large](https://huggingface.co/microsoft/DialoGPT-large).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Example:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START conversational_inference",
+"end-before": "END conversational_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_conversational_inference",
+"end-before": "END node_conversational_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_conversational_inference",
+"end-before": "END curl_conversational_inference",
+"dedent": 8}
+
+
+
+
+When sending your request, you should send a JSON encoded payload. Here
+are all the options
+
+| All parameters | |
+| :-------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required) | |
+| text (required) | The last input from the user in the conversation. |
+| generated_responses | A list of strings corresponding to the earlier replies from the model. |
+| past_user_inputs | A list of strings corresponding to the earlier replies from the user. Should be of the same length of `generated_responses`. |
+| **parameters** | a dict containing the following keys: |
+| min_length | (Default: `None`). Integer to define the minimum length **in tokens** of the output summary. |
+| max_length | (Default: `None`). Integer to define the maximum length **in tokens** of the output summary. |
+| top_k | (Default: `None`). Integer to define the top tokens considered within the `sample` operation to create new text. |
+| top_p | (Default: `None`). Float to define the tokens that are within the `sample` operation of text generation. Add tokens in the sample for more probable to least probable until the sum of the probabilities is greater than `top_p`. |
+| temperature | (Default: `1.0`). Float (0.0-100.0). The temperature of the sampling operation. 1 means regular sampling, `0` means always take the highest score, `100.0` is getting closer to uniform probability. |
+| repetition_penalty | (Default: `None`). Float (0.0-100.0). The more a token is used within generation the more it is penalized to not be picked in successive generation passes. |
+| max_time | (Default: `None`). Float (0-120.0). The amount of time in seconds that the query should take maximum. Network can cause some overhead so it will be a soft limit. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+| Returned values | |
+| :------------------ | :------------------------------------------------------------------------------------------------- |
+| **generated_text** | The answer of the bot |
+| **conversation** | A facility dictionnary to send back for the next input (with the new user input addition). |
+| past_user_inputs | List of strings. The last inputs from the user in the conversation, after the model has run. |
+| generated_responses | List of strings. The last outputs from the model in the conversation, after the model has run. |
+
+### Feature Extraction task
+
+This task reads some text and outputs raw float values, that are usually
+consumed as part of a semantic database/semantic search.
+
+
+
+**Recommended model**:
+[Sentence-transformers](https://huggingface.co/sentence-transformers/paraphrase-xlm-r-multilingual-v1).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+[Sentence-transformers](https://github.com/UKPLab/sentence-transformers)
+
+Request:
+
+| All parameters | |
+| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **inputs** (required): | a string or a list of strings to get the features from. |
+| **options** | a dict containing the following keys: |
+| use_cache | (Default: `true`). Boolean. There is a cache layer on the inference API to speedup requests we have already seen. Most models can use those results as is as models are deterministic (meaning the results will be the same anyway). However if you use a non deterministic model, you can set this parameter to prevent the caching mechanism from being used resulting in a real new query. |
+| wait_for_model | (Default: `false`) Boolean. If the model is not ready, wait for it instead of receiving 503. It limits the number of requests required to get your inference done. It is advised to only set this flag to true after receiving a 503 error as it will limit hanging in your application to known places. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+| Returned values | |
+| :---------------------------------------------- | :------------------------------------------------------------- |
+| **A list of float (or list of list of floats)** | The numbers that are the representation features of the input. |
+
+
+ Returned values are a list of floats, or a list of list of floats (depending
+ on if you sent a string or a list of string, and if the automatic reduction,
+ usually mean_pooling for instance was applied for you or not. This should be
+ explained on the model's README.
+
+
+## Audio
+
+### Automatic Speech Recognition task
+
+This task reads some audio input and outputs the said words within the
+audio files.
+
+
+
+**Recommended model**: [Check your
+langage](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition).
+
+
+
+
+
+**English**:
+[facebook/wav2vec2-large-960h-lv60-self](https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+[ESPnet](https://github.com/espnet/espnet) and
+[SpeechBrain](https://github.com/speechbrain/speechbrain)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START asr_inference",
+"end-before": "END asr_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_asr_inference",
+"end-before": "END node_asr_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_asr_inference",
+"end-before": "END curl_asr_inference",
+"dedent": 12}
+
+
+
+
+When sending your request, you should send a binary payload that simply
+contains your audio file. We try to support most formats (Flac, Wav,
+Mp3, Ogg etc\...). And we automatically rescale the sampling rate to the
+appropriate rate for the given model (usually 16KHz).
+
+| All parameters | |
+| :-------------------------- | :------------------------------------------------------------------------------------ |
+| **no parameter** (required) | a binary representation of the audio file. No other parameters are currently allowed. |
+
+Return value is either a dict or a list of dicts if you sent a list of inputs
+
+Response:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START asr_inference_answer",
+"end-before": "END asr_inference_answer",
+"dedent": 12}
+
+
+
+
+| Returned values | |
+| :-------------- | :---------------------------------------------------- |
+| **text** | The string that was recognized within the audio file. |
+
+### Audio Classification task
+
+This task reads some audio input and outputs the likelihood of classes.
+
+
+
+**Recommended model**:
+[superb/hubert-large-superb-er](https://huggingface.co/superb/hubert-large-superb-er).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+[SpeechBrain](https://github.com/speechbrain/speechbrain)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START aud_cls_inference",
+"end-before": "END aud_cls_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_aud_cls_inference",
+"end-before": "END node_aud_cls_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_aud_cls_inference",
+"end-before": "END curl_aud_cls_inference",
+"dedent": 12}
+
+
+
+
+When sending your request, you should send a binary payload that simply
+contains your audio file. We try to support most formats (Flac, Wav,
+Mp3, Ogg etc\...). And we automatically rescale the sampling rate to the
+appropriate rate for the given model (usually 16KHz).
+
+| All parameters | |
+| :-------------------------- | :------------------------------------------------------------------------------------ |
+| **no parameter** (required) | a binary representation of the audio file. No other parameters are currently allowed. |
+
+Return value is a dict
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START aud_cls_inference_answer",
+"end-before": "END aud_cls_inference_answer",
+"dedent": 12}
+
+
+
+
+| Returned values | |
+| :-------------- | :---------------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) |
+| **score** | A float that represents how likely it is that the audio file belongs to this class. |
+
+## Computer Vision
+
+### Image Classification task
+
+This task reads some image input and outputs the likelihood of classes.
+
+
+
+**Recommended model**:
+[google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START img_cls_inference",
+"end-before": "END img_cls_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_img_cls_inference",
+"end-before": "END node_img_cls_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_img_cls_inference",
+"end-before": "END curl_img_cls_inference",
+"dedent": 12}
+
+
+
+
+When sending your request, you should send a binary payload that simply
+contains your image file. We support all image formats [Pillow
+supports](https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html).
+
+| All parameters | |
+| :-------------------------- | :------------------------------------------------------------------------------------ |
+| **no parameter** (required) | a binary representation of the image file. No other parameters are currently allowed. |
+
+Return value is a dict
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START img_cls_inference_answer",
+"end-before": "END img_cls_inference_answer",
+"dedent": 12}
+
+
+
+
+| Returned values | |
+| :-------------- | :---------------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) |
+| **score** | A float that represents how likely it is that the image file belongs to this class. |
+
+### Object Detection task
+
+This task reads some image input and outputs the likelihood of classes &
+bounding boxes of detected objects.
+
+
+
+**Recommended model**:
+[facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START obj_det_inference",
+"end-before": "END obj_det_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_obj_det_inference",
+"end-before": "END node_obj_det_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_obj_det_inference",
+"end-before": "END curl_obj_det_inference",
+"dedent": 12}
+
+
+
+
+When sending your request, you should send a binary payload that simply
+contains your image file. We support all image formats [Pillow
+supports](https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html).
+
+| All parameters | |
+| :-------------------------- | :------------------------------------------------------------------------------------ |
+| **no parameter** (required) | a binary representation of the image file. No other parameters are currently allowed. |
+
+Return value is a dict
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START obj_det_inference_answer",
+"end-before": "END obj_det_inference_answer",
+"dedent": 12}
+
+
+
+
+| Returned values | |
+| :-------------- | :-------------------------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) of a detected object. |
+| **score** | A float that represents how likely it is that the detected object belongs to the given class. |
+| **box** | A dict (with keys [xmin,ymin,xmax,ymax]) representing the bounding box of a detected object. |
+
+### Image Segmentation task
+
+This task reads some image input and outputs the likelihood of classes &
+bounding boxes of detected objects.
+
+
+
+**Recommended model**:
+[facebook/detr-resnet-50-panoptic](https://huggingface.co/facebook/detr-resnet-50-panoptic).
+
+
+
+Available with: [🤗 Transformers](https://github.com/huggingface/transformers)
+
+Request:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START img_seg_inference",
+"end-before": "END img_seg_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_img_seg_inference",
+"end-before": "END node_img_seg_inference",
+"dedent": 12}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_img_seg_inference",
+"end-before": "END curl_img_seg_inference",
+"dedent": 12}
+
+
+
+
+When sending your request, you should send a binary payload that simply
+contains your image file. We support all image formats [Pillow
+supports](https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html).
+
+| All parameters | |
+| :-------------------------- | :------------------------------------------------------------------------------------ |
+| **no parameter** (required) | a binary representation of the image file. No other parameters are currently allowed. |
+
+Return value is a dict
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START img_seg_inference_answer",
+"end-before": "END img_seg_inference_answer",
+"dedent": 12}
+
+
+
+
+| Returned values | |
+| :-------------- | :--------------------------------------------------------------------------------------------- |
+| **label** | The label for the class (model specific) of a segment. |
+| **score** | A float that represents how likely it is that the segment belongs to the given class. |
+| **mask** | A str (base64 str of a single channel black-and-white img) representing the mask of a segment. |
diff --git a/docs/api-inference/faq.mdx b/docs/api-inference/faq.mdx
new file mode 100644
index 000000000..3a5bdb639
--- /dev/null
+++ b/docs/api-inference/faq.mdx
@@ -0,0 +1,32 @@
+# More information about the API
+
+## Rate limits
+
+The free Inference API may be rate limited for heavy use cases. We try to balance the loads evenly between all our
+available resources, and favoring steady flows of requests. If your account suddenly sends 10k requests then you're
+likely to receive 503 errors saying models are loading. In order to prevent that, you should instead try to start
+running queries smoothly from 0 to 10k over the course of a few minutes.
+
+## Running private models
+
+You can run private models by default ! If you don't see them on your
+[Hugging Face](https://huggingface.co) page please make sure you are
+logged in. Within the API make sure you include your token, otherwise
+your model will be declared as non existent.
+
+## Running a public model that I do not own
+
+You can. Please check the model card for any licensing issue that might
+arise, but most public models are delivered by researchers and are
+usable within commercial products. But please double check.
+
+## Finetuning a public model
+
+To automatically finetune a model on your data, please try [AutoTrain](https://huggingface.co/autotrain). It's a
+hands-free solution for automatically training and deploying a model; all you have to do is upload your data!
+
+## Running the inference on my infrastructure
+
+To run on premise inference on your own infrastructure, please contact our team to [request a
+demo](https://huggingface.co/platform#form) for more information about our [Private
+Hub](https://huggingface.co/platform).
diff --git a/docs/api-inference/index.mdx b/docs/api-inference/index.mdx
new file mode 100644
index 000000000..c613c5284
--- /dev/null
+++ b/docs/api-inference/index.mdx
@@ -0,0 +1,54 @@
+
+
+# 🤗 Hosted Inference API
+
+Test and evaluate, for free, over 80,000 publicly accessible machine learning models, or your own private models, via simple HTTP requests, with fast inference hosted on Hugging Face shared infrastructure.
+
+
+
+The Inference API is free to use, and rate limited. If you need an inference solution for production, check out our [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) service. With Inference Endpoints, you can easily deploy any machine learning model on dedicated and fully managed infrastructure. Select the cloud, region, compute instance, autoscaling range and security level to match your model, latency, throughput, and compliance needs.
+
+
+
+## Main features:
+
+- Get predictions from **80,000+ Transformers models** (T5, Blenderbot, Bart, GPT-2, Pegasus\...)
+- Switch from one model to the next by just switching the model ID
+- Use built-in integrations with **over 20 Open-Source libraries** (spaCy, SpeechBrain, etc).
+- Upload, manage and serve your **own models privately**
+- Run Classification, Image Segmentation, Automatic Speech Recognition, NER, Conversational, Summarization, Translation, Question-Answering, Embeddings Extraction tasks
+- Out of the box accelerated inference on **CPU** powered by Intel Xeon Ice Lake
+
+## Third-party library models:
+
+- The [Hub](https://huggingface.co) now supports many new libraries:
+
+ - [SpaCy](https://spacy.io/), [AllenNLP](https://allennlp.org/),
+ - [Speechbrain](https://speechbrain.github.io/),
+ - [Timm](https://pypi.org/project/timm/) and [many others](https://huggingface.co/docs/hub/libraries)...
+
+- Those models are enabled on the API thanks to some docker integration [api-inference-community](https://github.com/huggingface/huggingface_hub/tree/main/api-inference-community).
+
+
+
+Please note however, that these models will not allow you ([tracking issue](https://github.com/huggingface/huggingface_hub/issues/85)):
+
+- To get full optimization
+- To run private models
+- To get access to GPU inference
+
+
+
+## If you are looking for custom support from the Hugging Face team
+
+
+  +
+
+
+## Hugging Face is trusted in production by over 10,000 companies
+
+ +
+ +
+
+
diff --git a/docs/api-inference/parallelism.mdx b/docs/api-inference/parallelism.mdx
new file mode 100644
index 000000000..8f80f72f3
--- /dev/null
+++ b/docs/api-inference/parallelism.mdx
@@ -0,0 +1,119 @@
+# Parallelism and batch jobs
+
+In order to get your answers as quickly as possible, you probably want
+to run some kind of parallelism on your jobs.
+
+There are two options at your disposal for this.
+
+- The streaming option
+- The dataset option
+
+## Streaming
+
+In order to maximize the speed of inference, instead of running many
+HTTP requests it will be more efficient to stream your data to the API.
+This will require the use of websockets on your end. Internally we're
+using a queue system where machines can variously pull work, seamlessly
+using parallelism for you. **This is meant as a batching mechanism and a
+single stream should be open at any give time**. If multiple streams are
+open, requests will go to either without any guarantee. This is intended
+as it allows recovering from a stream cut. Simply reinitializing the
+stream will recover results, everything that was sent is being processed
+even if you are not connected anymore. So make sure you don't send item
+multiple times other wise you will be billed multiple times.
+
+Here is a small example:
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "python",
+"start-after": "START python_parallelism",
+"end-before": "END python_parallelism",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "js",
+"start-after": "START node_parallelism",
+"end-before": "END node_parallelism",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "bash",
+"start-after": "START curl_parallelism",
+"end-before": "END curl_parallelism",
+"dedent": 8}
+
+
+
+
+The messages you need to send need to contain inputs keys.
+
+Optionnally you can specifiy id key that will be sent back
+with the result. We try to maintain the ordering of results as you sent,
+but it's better to be sure, the id key is there for that.
+
+Optionnally, you can specify parameters key that
+corresponds to `detailed_parameters` of
+the pipeline you are using.
+
+The received messages will _always_ contain a type key.
+
+- status message: These messages will contain a
+ message key that will inform you about the current
+ status of the job
+- results message: These messages will contain the
+ actual results of the computation. id will contain the
+ id you have sent (or one will be generated automatically).
+ outputs will contain the result like it would be sent
+ by the HTTP endpoint. See `detailed_parameters` for more information.
+
+## Dataset
+
+If you are running regularly against the same dataset to check
+differences between models or drifts we recommend using a
+[dataset](https://huggingface.co/docs/datasets/) .
+
+Or use any of the 2000 available datasets:
+[here](https://huggingface.co/datasets).
+
+The outputs of this method will automatically create a private dataset
+on your account, and use git mechanisms to store versions of the various
+outputs.
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "python",
+"start-after": "START python_parallelism_datasets",
+"end-before": "END python_parallelism_datasets",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "node",
+"start-after": "START node_parallelism_datasets",
+"end-before": "END node_parallelism_datasets",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "bash",
+"start-after": "START curl_parallelism_datasets",
+"end-before": "END curl_parallelism_datasets",
+"dedent": 8}
+
+
+
diff --git a/docs/api-inference/quicktour.mdx b/docs/api-inference/quicktour.mdx
new file mode 100644
index 000000000..4b8d9fc13
--- /dev/null
+++ b/docs/api-inference/quicktour.mdx
@@ -0,0 +1,107 @@
+# Overview
+
+Let's have a quick look at the 🤗 Hosted Inference API.
+
+## Main features:
+
+- Leverage **80,000+ Transformer models** (T5, Blenderbot, Bart, GPT-2, Pegasus\...)
+- Upload, manage and serve your **own models privately**
+- Run Classification, NER, Conversational, Summarization, Translation, Question-Answering, Embeddings Extraction tasks
+- Get up to **10x inference speedup** to reduce user latency
+- Accelerated inference for a number of supported models on CPU
+- Run **large models** that are challenging to deploy in production
+- Scale up to 1,000 requests per second with **automatic scaling** built-in
+- **Ship new NLP, CV, Audio, or RL features faster** as new models become available
+- Build your business on a platform powered by the reference open source project in ML
+
+## Get your API Token
+
+To get started you need to:
+
+- [Register](https://huggingface.co/join) or [Login](https://huggingface.co/login).
+- Get a User Access or API token [in your Hugging Face profile settings](https://huggingface.co/settings/tokens).
+
+You should see a token `hf_xxxxx` (old tokens are `api_XXXXXXXX` or `api_org_XXXXXXX`).
+
+If you do not submit your API token when sending requests to the API,
+you will not be able to run inference on your private models.
+
+## Running Inference with API Requests
+
+The first step is to choose which model you are going to run. Go to the
+[Model Hub](https://huggingface.co/models) and select the model you want
+to use. If you are unsure where to start, make sure to check the
+[recommended models for each ML
+task](https://api-inference.huggingface.co/docs/python/html/detailed_parameters.html#detailed-parameters)
+available, or the [Tasks](https://huggingface.co/tasks) overview.
+
+```
+ENDPOINT = https://api-inference.huggingface.co/models/
+```
+
+Let's use [gpt2](https://huggingface.co/gpt2) as an example. To run
+inference, simply use this code:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START simple_inference",
+"end-before": "END simple_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_simple_inference",
+"end-before": "END node_simple_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_simple_inference",
+"end-before": "END curl_simple_inference",
+"dedent": 8}
+
+
+
+
+## API Options and Parameters
+
+Depending on the task (aka pipeline) the model is configured for, the
+request will accept specific parameters. When sending requests to run
+any model, API options allow you to specify the caching and model
+loading behavior. All API options and
+parameters are detailed here [`detailed_parameters`](detailed_parameters).
+
+## Using CPU-Accelerated Inference
+
+As an API customer, your API token will automatically enable CPU-Accelerated inference on your requests if the model type is supported. For instance, if you compare
+gpt2 model inference through our API with
+CPU-Acceleration, compared to running inference on the model out of the
+box on a local setup, you should measure a **\~10x speedup**. The
+specific performance boost depends on the model and input payload (and
+your local hardware).
+
+To verify you are using the CPU-Accelerated version of a model you can
+check the x-compute-type header of your requests, which
+should be cpu+optimized. If you do not see it, it simply
+means not all optimizations are turned on. This can be for various
+factors; the model might have been added recently to transformers, or
+the model can be optimized in several different ways and the best one
+depends on your use case.
+
+If you contact us at api-enterprise@huggingface.co, we'll be able to
+increase the inference speed for you, depending on your actual use case.
+
+## Model Loading and latency
+
+The Hosted Inference API can serve predictions on-demand from over 100,000 models deployed on the Hugging Face Hub, dynamically loaded on shared infrastructure. If the requested model is not loaded in memory, the Hosted Inference API will start by loading the model into memory and returning a 503 response, before it can respond with the prediction.
+
+If your use case requires large volume or predictable latencies, you can use our paid solution [Inference Endpoints](https://huggingface.co/inference-endpoints) to easily deploy your models on dedicated, fully-managed infrastructure. With Inference Endpoints you can quickly create endpoints on the cloud, region, CPU or GPU compute instance of your choice.
diff --git a/docs/api-inference/usage.mdx b/docs/api-inference/usage.mdx
new file mode 100644
index 000000000..66313f017
--- /dev/null
+++ b/docs/api-inference/usage.mdx
@@ -0,0 +1,105 @@
+# Detailed usage and pinned models
+
+## API Usage dashboard
+
+The [API Usage Dashboard](https://api-inference.huggingface.co/dashboard/) (beta) shows
+historical number of requests and input characters per model for an API Token.
+
+Please note that each user account, and each organization, has its own
+API Token. By default, you should
+not have anything to do. However, if you have any doubt about what's
+being shown to you, or you have a complex setup (user subscription,
+multiple organizations and so on), please contact api-entreprise@hugginface.co.
+
+
+
+
+
diff --git a/docs/api-inference/parallelism.mdx b/docs/api-inference/parallelism.mdx
new file mode 100644
index 000000000..8f80f72f3
--- /dev/null
+++ b/docs/api-inference/parallelism.mdx
@@ -0,0 +1,119 @@
+# Parallelism and batch jobs
+
+In order to get your answers as quickly as possible, you probably want
+to run some kind of parallelism on your jobs.
+
+There are two options at your disposal for this.
+
+- The streaming option
+- The dataset option
+
+## Streaming
+
+In order to maximize the speed of inference, instead of running many
+HTTP requests it will be more efficient to stream your data to the API.
+This will require the use of websockets on your end. Internally we're
+using a queue system where machines can variously pull work, seamlessly
+using parallelism for you. **This is meant as a batching mechanism and a
+single stream should be open at any give time**. If multiple streams are
+open, requests will go to either without any guarantee. This is intended
+as it allows recovering from a stream cut. Simply reinitializing the
+stream will recover results, everything that was sent is being processed
+even if you are not connected anymore. So make sure you don't send item
+multiple times other wise you will be billed multiple times.
+
+Here is a small example:
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "python",
+"start-after": "START python_parallelism",
+"end-before": "END python_parallelism",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "js",
+"start-after": "START node_parallelism",
+"end-before": "END node_parallelism",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "bash",
+"start-after": "START curl_parallelism",
+"end-before": "END curl_parallelism",
+"dedent": 8}
+
+
+
+
+The messages you need to send need to contain inputs keys.
+
+Optionnally you can specifiy id key that will be sent back
+with the result. We try to maintain the ordering of results as you sent,
+but it's better to be sure, the id key is there for that.
+
+Optionnally, you can specify parameters key that
+corresponds to `detailed_parameters` of
+the pipeline you are using.
+
+The received messages will _always_ contain a type key.
+
+- status message: These messages will contain a
+ message key that will inform you about the current
+ status of the job
+- results message: These messages will contain the
+ actual results of the computation. id will contain the
+ id you have sent (or one will be generated automatically).
+ outputs will contain the result like it would be sent
+ by the HTTP endpoint. See `detailed_parameters` for more information.
+
+## Dataset
+
+If you are running regularly against the same dataset to check
+differences between models or drifts we recommend using a
+[dataset](https://huggingface.co/docs/datasets/) .
+
+Or use any of the 2000 available datasets:
+[here](https://huggingface.co/datasets).
+
+The outputs of this method will automatically create a private dataset
+on your account, and use git mechanisms to store versions of the various
+outputs.
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "python",
+"start-after": "START python_parallelism_datasets",
+"end-before": "END python_parallelism_datasets",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "node",
+"start-after": "START node_parallelism_datasets",
+"end-before": "END node_parallelism_datasets",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_parallelism.py",
+"language": "bash",
+"start-after": "START curl_parallelism_datasets",
+"end-before": "END curl_parallelism_datasets",
+"dedent": 8}
+
+
+
diff --git a/docs/api-inference/quicktour.mdx b/docs/api-inference/quicktour.mdx
new file mode 100644
index 000000000..4b8d9fc13
--- /dev/null
+++ b/docs/api-inference/quicktour.mdx
@@ -0,0 +1,107 @@
+# Overview
+
+Let's have a quick look at the 🤗 Hosted Inference API.
+
+## Main features:
+
+- Leverage **80,000+ Transformer models** (T5, Blenderbot, Bart, GPT-2, Pegasus\...)
+- Upload, manage and serve your **own models privately**
+- Run Classification, NER, Conversational, Summarization, Translation, Question-Answering, Embeddings Extraction tasks
+- Get up to **10x inference speedup** to reduce user latency
+- Accelerated inference for a number of supported models on CPU
+- Run **large models** that are challenging to deploy in production
+- Scale up to 1,000 requests per second with **automatic scaling** built-in
+- **Ship new NLP, CV, Audio, or RL features faster** as new models become available
+- Build your business on a platform powered by the reference open source project in ML
+
+## Get your API Token
+
+To get started you need to:
+
+- [Register](https://huggingface.co/join) or [Login](https://huggingface.co/login).
+- Get a User Access or API token [in your Hugging Face profile settings](https://huggingface.co/settings/tokens).
+
+You should see a token `hf_xxxxx` (old tokens are `api_XXXXXXXX` or `api_org_XXXXXXX`).
+
+If you do not submit your API token when sending requests to the API,
+you will not be able to run inference on your private models.
+
+## Running Inference with API Requests
+
+The first step is to choose which model you are going to run. Go to the
+[Model Hub](https://huggingface.co/models) and select the model you want
+to use. If you are unsure where to start, make sure to check the
+[recommended models for each ML
+task](https://api-inference.huggingface.co/docs/python/html/detailed_parameters.html#detailed-parameters)
+available, or the [Tasks](https://huggingface.co/tasks) overview.
+
+```
+ENDPOINT = https://api-inference.huggingface.co/models/
+```
+
+Let's use [gpt2](https://huggingface.co/gpt2) as an example. To run
+inference, simply use this code:
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "python",
+"start-after": "START simple_inference",
+"end-before": "END simple_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "node",
+"start-after": "START node_simple_inference",
+"end-before": "END node_simple_inference",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_inference.py",
+"language": "bash",
+"start-after": "START curl_simple_inference",
+"end-before": "END curl_simple_inference",
+"dedent": 8}
+
+
+
+
+## API Options and Parameters
+
+Depending on the task (aka pipeline) the model is configured for, the
+request will accept specific parameters. When sending requests to run
+any model, API options allow you to specify the caching and model
+loading behavior. All API options and
+parameters are detailed here [`detailed_parameters`](detailed_parameters).
+
+## Using CPU-Accelerated Inference
+
+As an API customer, your API token will automatically enable CPU-Accelerated inference on your requests if the model type is supported. For instance, if you compare
+gpt2 model inference through our API with
+CPU-Acceleration, compared to running inference on the model out of the
+box on a local setup, you should measure a **\~10x speedup**. The
+specific performance boost depends on the model and input payload (and
+your local hardware).
+
+To verify you are using the CPU-Accelerated version of a model you can
+check the x-compute-type header of your requests, which
+should be cpu+optimized. If you do not see it, it simply
+means not all optimizations are turned on. This can be for various
+factors; the model might have been added recently to transformers, or
+the model can be optimized in several different ways and the best one
+depends on your use case.
+
+If you contact us at api-enterprise@huggingface.co, we'll be able to
+increase the inference speed for you, depending on your actual use case.
+
+## Model Loading and latency
+
+The Hosted Inference API can serve predictions on-demand from over 100,000 models deployed on the Hugging Face Hub, dynamically loaded on shared infrastructure. If the requested model is not loaded in memory, the Hosted Inference API will start by loading the model into memory and returning a 503 response, before it can respond with the prediction.
+
+If your use case requires large volume or predictable latencies, you can use our paid solution [Inference Endpoints](https://huggingface.co/inference-endpoints) to easily deploy your models on dedicated, fully-managed infrastructure. With Inference Endpoints you can quickly create endpoints on the cloud, region, CPU or GPU compute instance of your choice.
diff --git a/docs/api-inference/usage.mdx b/docs/api-inference/usage.mdx
new file mode 100644
index 000000000..66313f017
--- /dev/null
+++ b/docs/api-inference/usage.mdx
@@ -0,0 +1,105 @@
+# Detailed usage and pinned models
+
+## API Usage dashboard
+
+The [API Usage Dashboard](https://api-inference.huggingface.co/dashboard/) (beta) shows
+historical number of requests and input characters per model for an API Token.
+
+Please note that each user account, and each organization, has its own
+API Token. By default, you should
+not have anything to do. However, if you have any doubt about what's
+being shown to you, or you have a complex setup (user subscription,
+multiple organizations and so on), please contact api-entreprise@hugginface.co.
+
+ +
+## Pinned models
+
+
+
+Model pinning is only supported for existing customers.
+
+If you're interested in having a model that you can [readily deploy for
+inference](https://ui.endpoints.huggingface.co/new), take a look at our [Inference
+Endpoints](https://huggingface.co/inference-endpoints) solution! It is a secure production environment with dedicated
+and autoscaling infrastructure, and you have the flexibility to choose between CPU and GPU resources.
+
+
+
+A pinned model is a model which is preloaded for inference and instantly
+available for requests authenticated with an API Token.
+
+You can set pinned models to your API Token in the API Usage dashboard.
+
+[Pinned models](https://api-inference.huggingface.co/dashboard/pinned_models)
+
+Model pinning is also accessible directly from the API. Here is how you
+see what your current pinned models are :
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "python",
+"start-after": "START python_pinning",
+"end-before": "END python_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "node",
+"start-after": "START node_pinning",
+"end-before": "END node_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "bash",
+"start-after": "START curl_pinning",
+"end-before": "END curl_pinning",
+"dedent": 8}
+
+
+
+
+Pinning models is done that way.
+
+
+
+Be careful, you need to specify ALL the pinned models each time !
+
+
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "python",
+"start-after": "START python_set_pinning",
+"end-before": "END python_set_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "node",
+"start-after": "START node_set_pinning",
+"end-before": "END node_set_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "bash",
+"start-after": "START curl_set_pinning",
+"end-before": "END curl_set_pinning",
+"dedent": 8}
+
+
+
+
+## Pinned models
+
+
+
+Model pinning is only supported for existing customers.
+
+If you're interested in having a model that you can [readily deploy for
+inference](https://ui.endpoints.huggingface.co/new), take a look at our [Inference
+Endpoints](https://huggingface.co/inference-endpoints) solution! It is a secure production environment with dedicated
+and autoscaling infrastructure, and you have the flexibility to choose between CPU and GPU resources.
+
+
+
+A pinned model is a model which is preloaded for inference and instantly
+available for requests authenticated with an API Token.
+
+You can set pinned models to your API Token in the API Usage dashboard.
+
+[Pinned models](https://api-inference.huggingface.co/dashboard/pinned_models)
+
+Model pinning is also accessible directly from the API. Here is how you
+see what your current pinned models are :
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "python",
+"start-after": "START python_pinning",
+"end-before": "END python_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "node",
+"start-after": "START node_pinning",
+"end-before": "END node_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "bash",
+"start-after": "START curl_pinning",
+"end-before": "END curl_pinning",
+"dedent": 8}
+
+
+
+
+Pinning models is done that way.
+
+
+
+Be careful, you need to specify ALL the pinned models each time !
+
+
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "python",
+"start-after": "START python_set_pinning",
+"end-before": "END python_set_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "node",
+"start-after": "START node_set_pinning",
+"end-before": "END node_set_pinning",
+"dedent": 8}
+
+
+
+
+{"path": "../../tests/documentation/test_pinning.py",
+"language": "bash",
+"start-after": "START curl_set_pinning",
+"end-before": "END curl_set_pinning",
+"dedent": 8}
+
+
+